10 Derivative Rules
We have defined the differential df_a of a function f at a point a as the linear map that captures the first-order behavior of f near a. We have seen how this notion underlies local linear approximation and connects to global properties via the Mean Value Theorem.
The natural next step is to understand how differentials behave under basic operations on functions. Given functions f and g differentiable at a, we determine the differentials of f+g, f \cdot g, f/g, and compositions f \circ g at a.
Formally, we seek algebraic rules for combining linear maps: each rule expresses the differential of a new function in terms of the differentials of its constituent functions. This provides a systematic method to compute differentials for complex functions without leaving the linear map framework. (To check your results computationally, try our derivative calculator.)
10.1 Linearity
Recall that if f is differentiable at a, the differential df_a : \mathbb{R} \to \mathbb{R}, \quad df_a(h) = f'(a)h is a linear functional: it takes a displacement h and returns the approximate change in f at a.
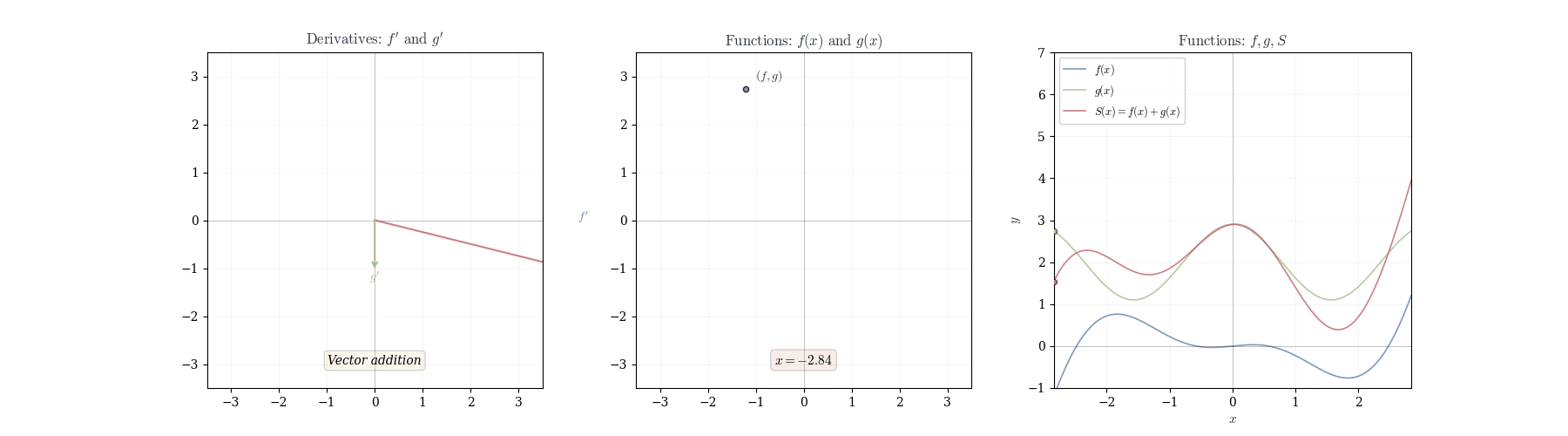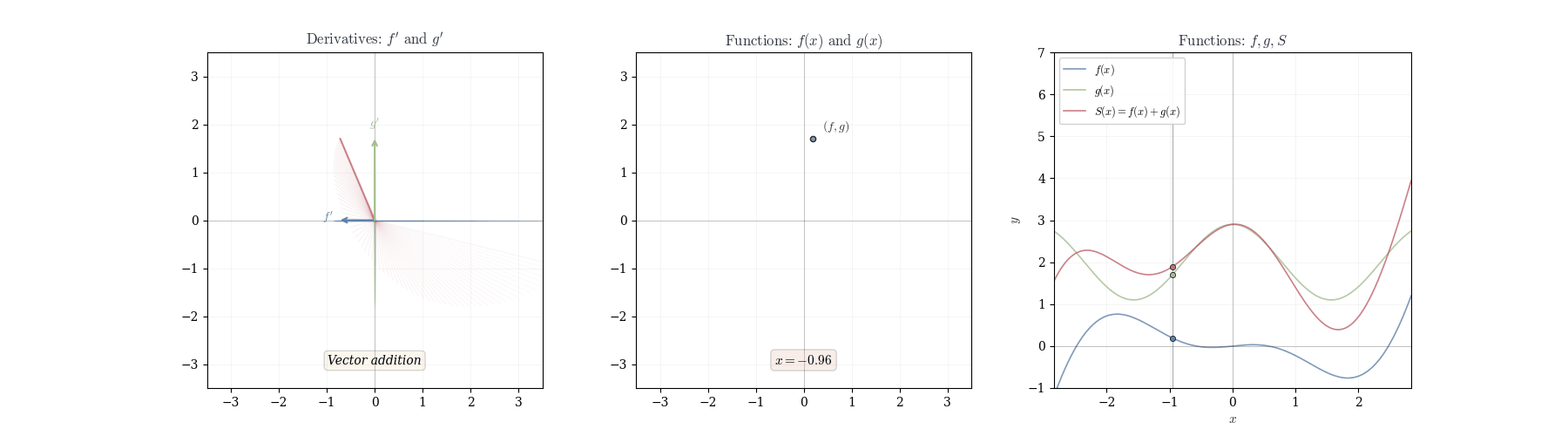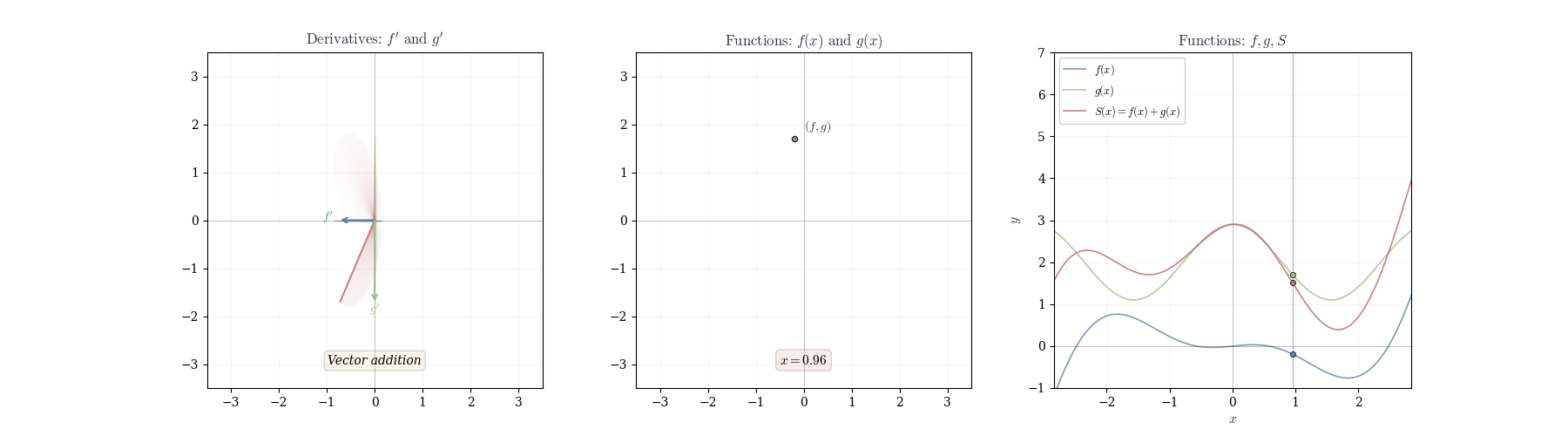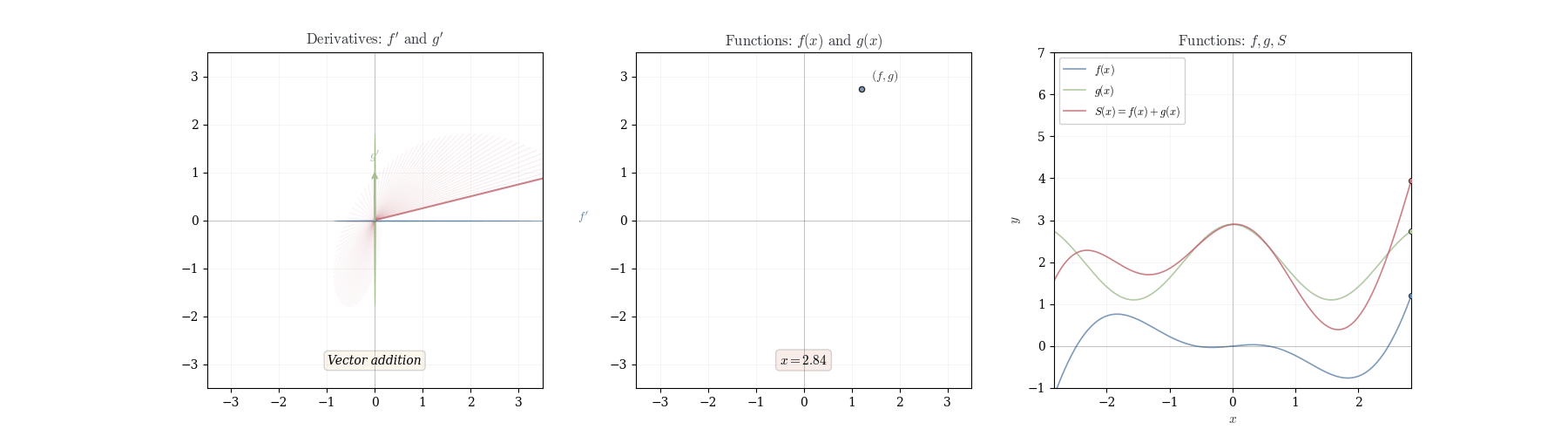
The linearity of df_a immediately yields rules for sums and scalar multiples.
Theorem 10.1 (Sum Rule) If f and g are differentiable at a, then f + g is differentiable at a with d_a(f+g)(h) = df_a(h) + dg_a(h).
In coordinates: (f+g)'(a) = f'(a) + g'(a).
Since df_a and dg_a are linear functionals, their sum is linear. For any displacement h, (f+g)(a+h) = f(a+h) + g(a+h) = [f(a) + df_a(h) + o(h)] + [g(a) + dg_a(h) + o(h)].
Rearranging, (f+g)(a+h) = (f+g)(a) + [df_a(h) + dg_a(h)] + o(h).
Thus d_a(f+g)(h) = df_a(h) + dg_a(h). \square
Theorem 10.2 (Scalar Multiplication) If f is differentiable at a and c \in \mathbb{R}, then cf is differentiable at a with d_a(cf)(h) = c \cdot df_a(h).
In coordinates: (cf)'(a) = c \cdot f'(a).
For any displacement h, (cf)(a+h) = c \cdot f(a+h) = c[f(a) + df_a(h) + o(h)] = cf(a) + c \cdot df_a(h) + o(h).
Thus d_a(cf)(h) = c \cdot df_a(h). \square
Theorem 10.3 (Difference Rule) If f and g are differentiable at a, then f - g is differentiable at a with d_a(f-g)(h) = df_a(h) - dg_a(h).
In coordinates: (f-g)'(a) = f'(a) - g'(a).
Observe that f - g = f + (-1) \cdot g. By the sum rule and scalar multiplication rule we have
d_a(f-g)(h) = d_a(f + (-1) \cdot g)(h) = df_a(h) + d_a((-1) \cdot g)(h) = df_a(h) - dg_a(h).
As required. \square
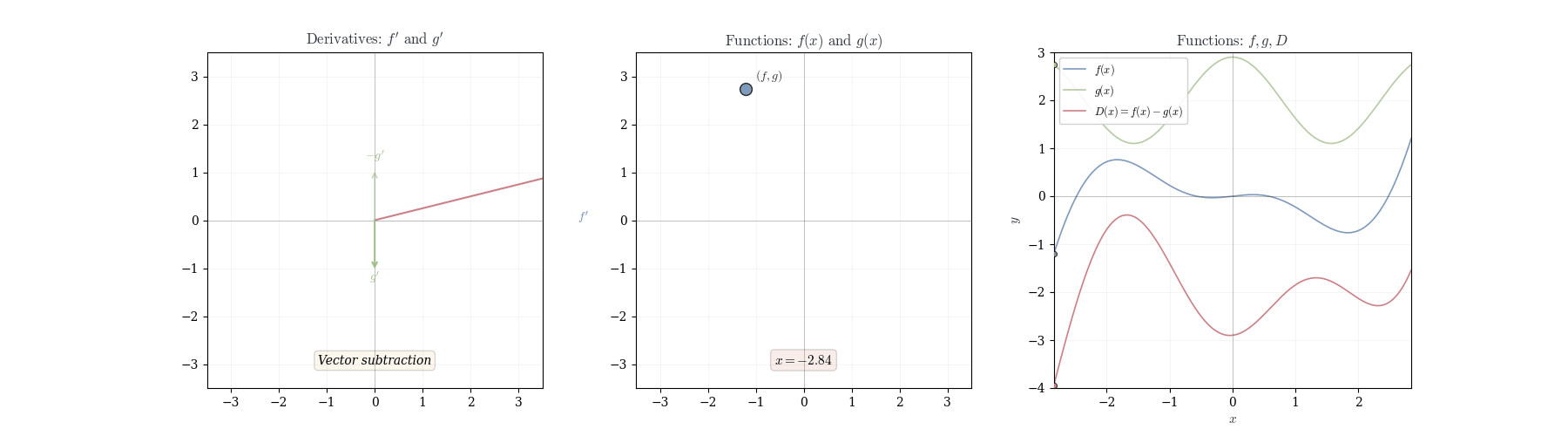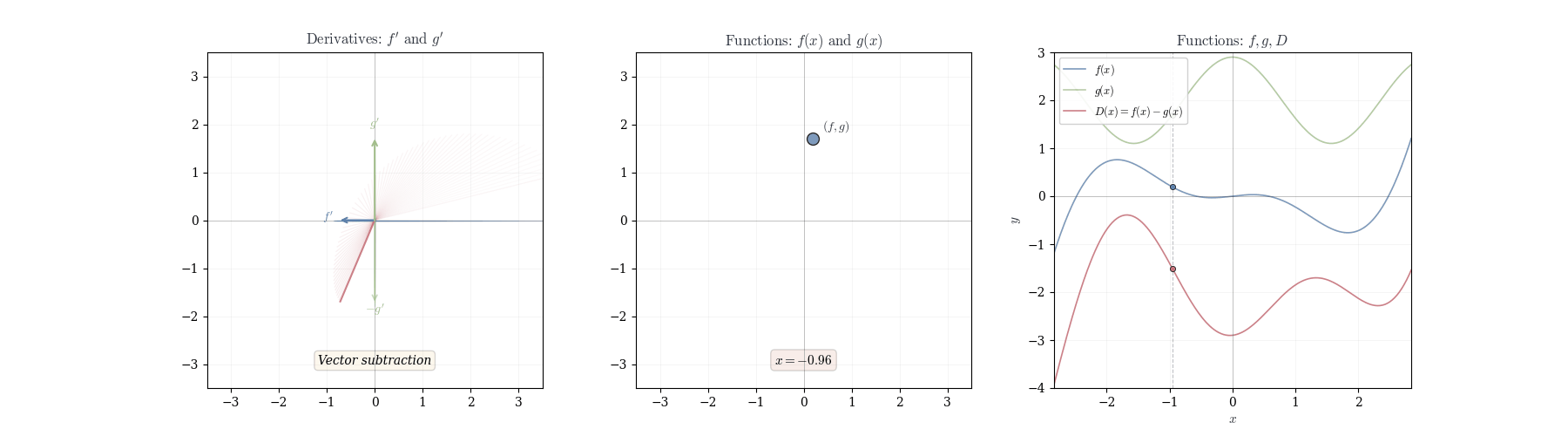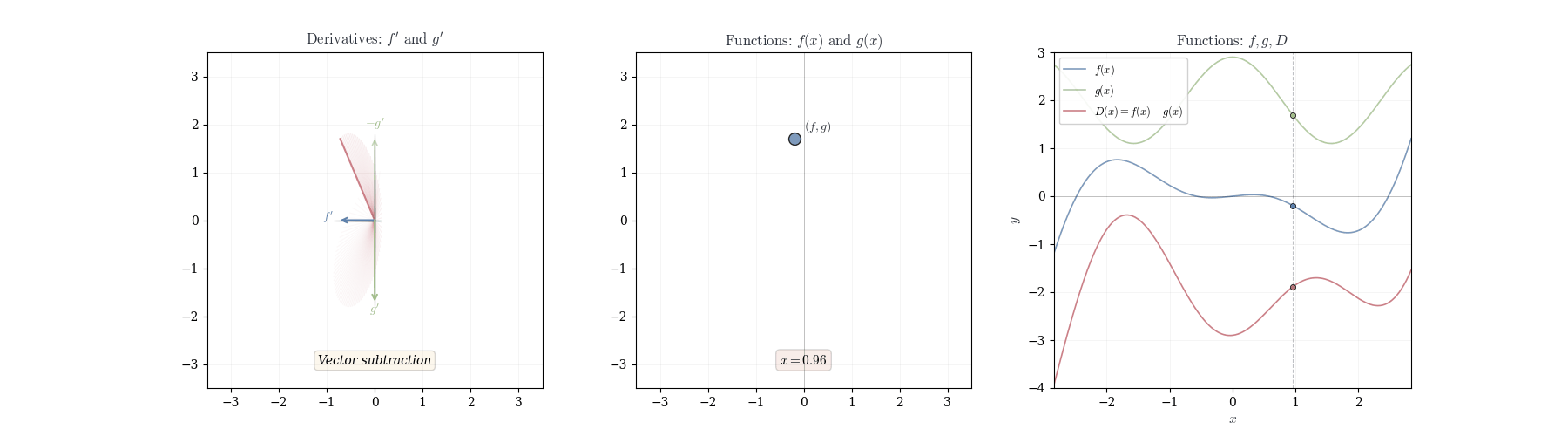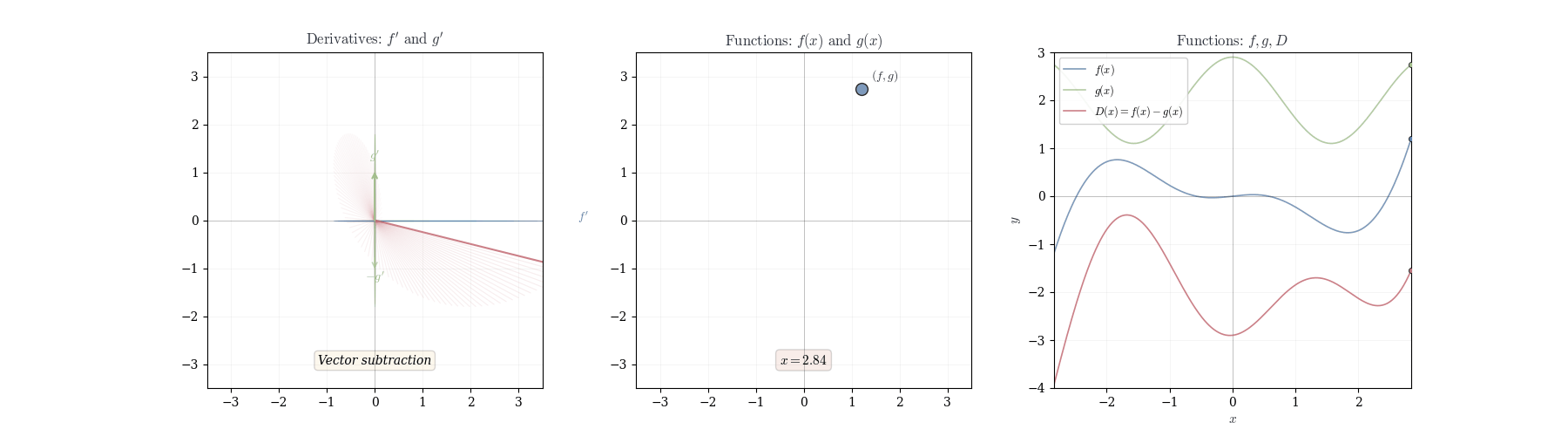
10.2 Product Rule
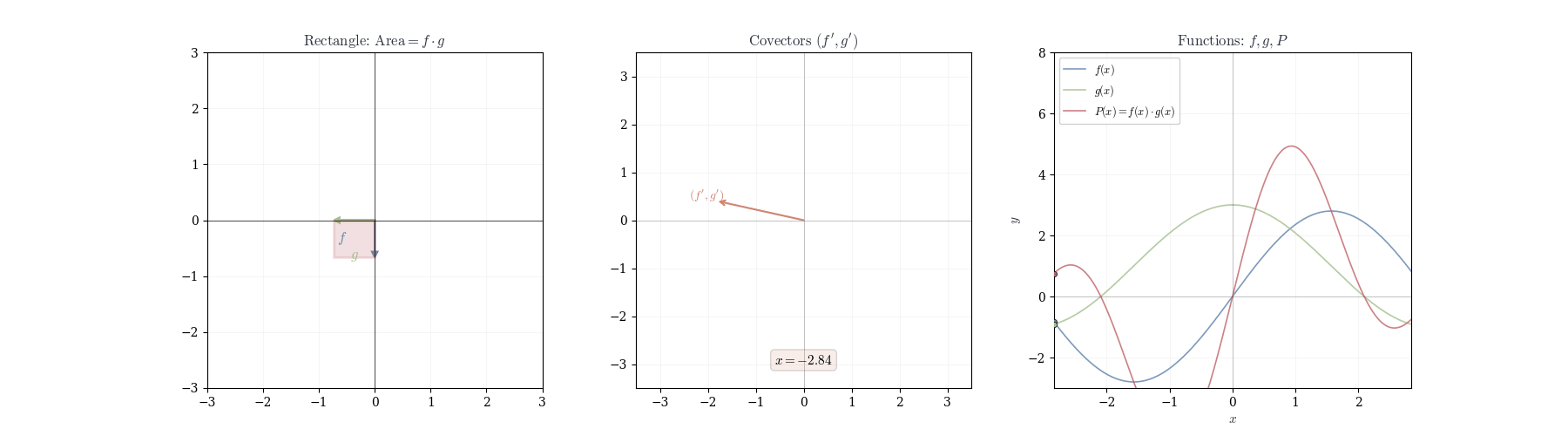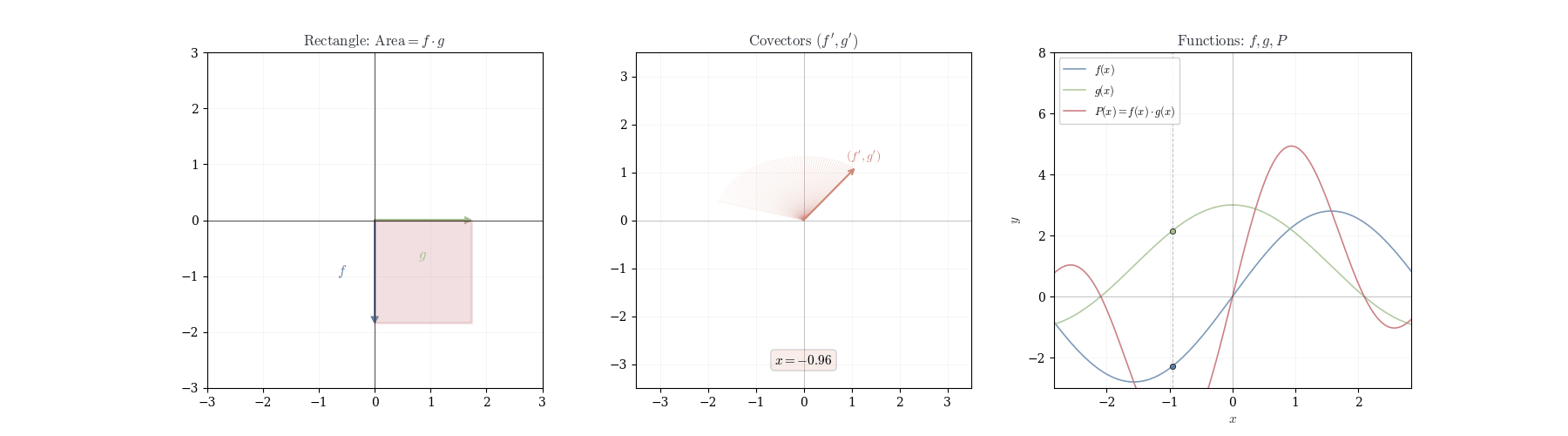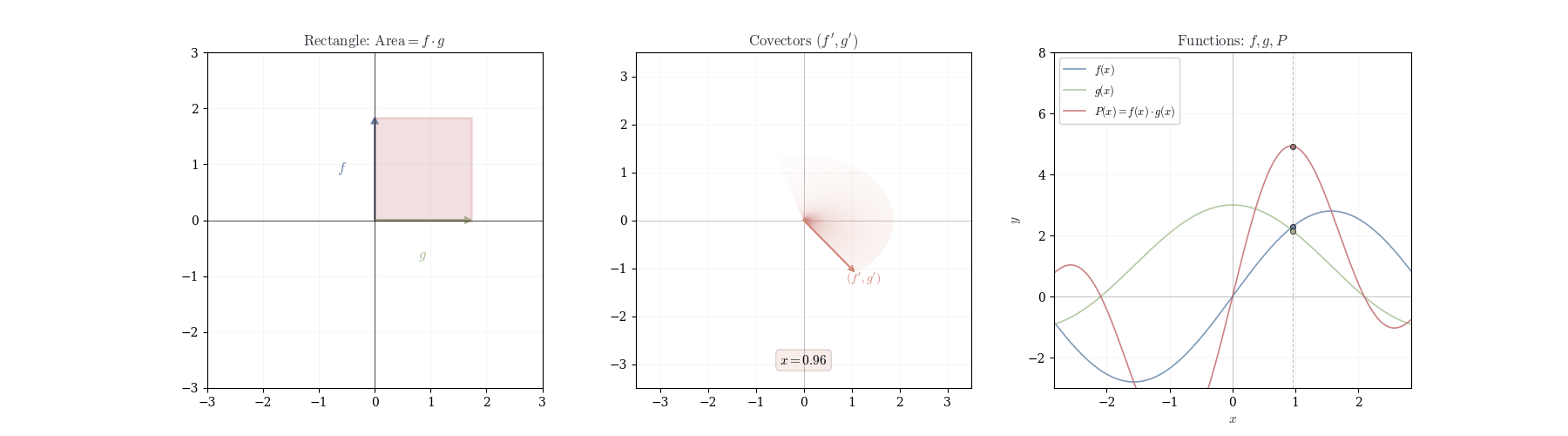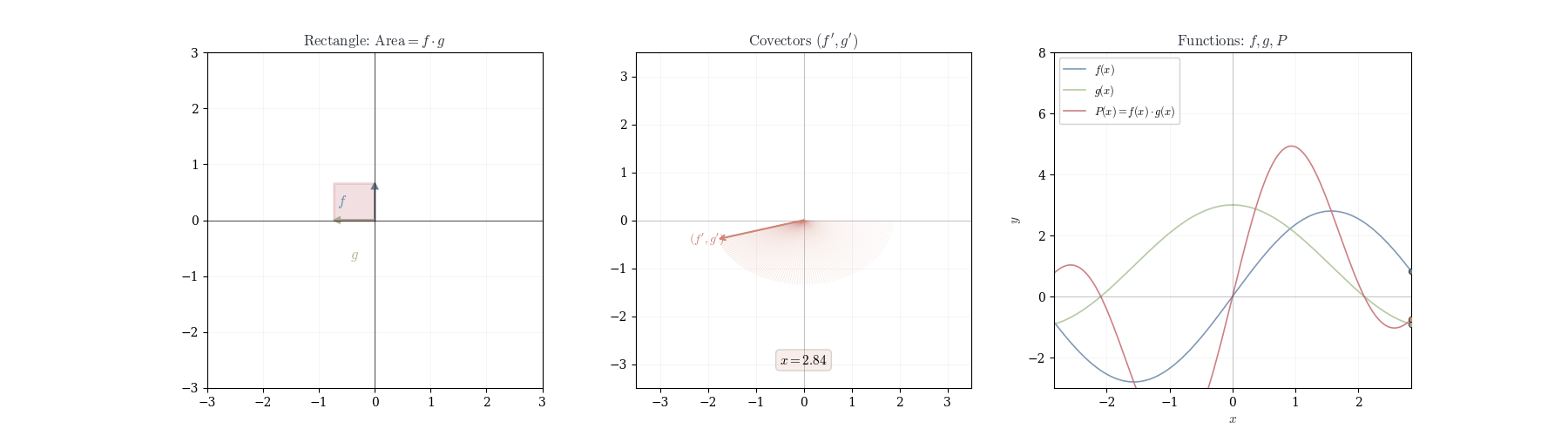
The map (f, g) \mapsto fg is bilinear: it is linear in each argument separately but not linear in both simultaneously. Consequently, the differential of a product cannot be the product of differentials; the correct formula combines the values of the functions at the base point with the differentials of the other factor.
Theorem 10.4 (Product Rule) If f and g are differentiable at a, then f \cdot g is differentiable at a with d_a(fg)(h) = f(a) \, dg_a(h) + g(a) \, df_a(h).
In coordinates: (fg)'(a) = f(a) g'(a) + f'(a) g(a).
By differentiability, there exist linear maps df_a and dg_a such that f(a+h) = f(a) + df_a(h) + o_f(h), \quad g(a+h) = g(a) + dg_a(h) + o_g(h), where o_f(h)/h \to 0 and o_g(h)/h \to 0 as h \to 0.
Consider the product \begin{align*} (fg)(a+h) &= f(a+h) \, g(a+h) \\ &= [f(a) + df_a(h) + o_f(h)] \, [g(a) + dg_a(h) + o_g(h)]. \end{align*}
Expanding, \begin{align*} (fg)(a+h) &= f(a)g(a) + f(a) \, dg_a(h) + f(a) \, o_g(h) \\ &\quad + g(a) \, df_a(h) + df_a(h) \, dg_a(h) + df_a(h) \, o_g(h) \\ &\quad + o_f(h) \, g(a) + o_f(h) \, dg_a(h) + o_f(h) \, o_g(h). \end{align*}
We claim all terms except f(a) \, dg_a(h) + g(a) \, df_a(h) are o(h).
Since df_a(h) = f'(a)h and dg_a(h) = g'(a)h, the cross term satisfies \left|\frac{df_a(h) \, dg_a(h)}{h}\right| = \left|\frac{f'(a)h \cdot g'(a)h}{h}\right| = |f'(a)g'(a)||h| \to 0.
For terms like f(a) \, o_g(h): \left|\frac{f(a) \, o_g(h)}{h}\right| = |f(a)| \left|\frac{o_g(h)}{h}\right| \to 0.
For terms like df_a(h) \, o_g(h): \left|\frac{df_a(h) \, o_g(h)}{h}\right| = \left|\frac{f'(a)h \cdot o_g(h)}{h}\right| = |f'(a)| \left|\frac{o_g(h)h}{h}\right| = |f'(a)| \left|o_g(h)\right| \to 0.
Similar arguments apply to all other terms. Therefore, (fg)(a+h) = f(a)g(a) + f(a) \, dg_a(h) + g(a) \, df_a(h) + o(h), showing d_a(fg)(h) = f(a) \, dg_a(h) + g(a) \, df_a(h). \square
10.3 The Chain Rule
The rules for sums and products follow almost immediately from linearity of differentials. The chain rule, however, requires more care. To understand why this rule matters, consider a classical problem from mechanics.
In the 18th century, Lagrange introduced a way to describe motion through energy. Even in one dimension, his framework illustrates why derivatives of compositions arise naturally.
Consider a particle of mass m moving under uniform gravity g. Its kinetic energy depends on velocity, and its potential energy depends on position. Both vary with time, giving the Lagrangian \mathscr{L}(t) = K(v(t)) - U(x(t)), where x(t) is the particle’s height, v(t) = x'(t) is its velocity, K(v) = \frac{1}{2}mv^2 is kinetic energy, and U(x) = mgx is potential energy.
The Lagrangian is a composition: it depends on x and v, which themselves depend on t. The rate of change of \mathscr{L} comes from contributions of both position and velocity, weighted by the Lagrangian’s sensitivity to each. The particle’s energy changes because both position and velocity change. To understand this evolution, we multiply the rate of change of each quantity by the rate at which that quantity itself changes.
This is the mechanism captured by the chain rule. Even in this simple one-dimensional case, differentiating a function of a function is essential.
10.3.1 Formulation
We determine how the derivative of a composition f \circ g relates to the derivatives of f and g.
Theorem 10.5 (Chain Rule) Let g be differentiable at a and f differentiable at g(a). Then f \circ g is differentiable at a with d_a(f \circ g)(h) = df_{g(a)}\big(dg_a(h)\big).
In coordinates: (f \circ g)'(a) = f'(g(a)) \cdot g'(a).
By differentiability, there exist linear maps dg_a and df_{g(a)} such that g(a+h) = g(a) + dg_a(h) + o_g(h), \quad h \to 0, and f(g(a)+k) = f(g(a)) + df_{g(a)}(k) + o_f(k), \quad k \to 0.
Set k = g(a+h) - g(a) = dg_a(h) + o_g(h). Then f(g(a+h)) = f(g(a)) + df_{g(a)}(k) + o_f(k).
Since df_{g(a)} is linear, we have df_{g(a)}(k) = df_{g(a)}(dg_a(h)) + df_{g(a)}(o_g(h)).
Claim 1: df_{g(a)}(o_g(h)) is o(h).
Since df_{g(a)}(k) = f'(g(a)) \cdot k, we have \left|\frac{df_{g(a)}(o_g(h))}{h}\right| = \left|\frac{f'(g(a)) \cdot o_g(h)}{h}\right| = |f'(g(a))| \left|\frac{o_g(h)}{h}\right| \to 0.
Claim 2: o_f(k) is o(h).
We must show |o_f(k)|/|h| \to 0 as h \to 0. Since k = dg_a(h) + o_g(h) and dg_a(h) = g'(a)h, we have |k| \leq |g'(a)||h| + |o_g(h)|.
For sufficiently small h, |o_g(h)|/|h| < 1, so |o_g(h)| < |h|. Therefore, |k| \leq (|g'(a)| + 1)|h| =: C|h| for some constant C > 0.
Now, as h \to 0, we have k \to 0, so \frac{|o_f(k)|}{|h|} = \frac{|o_f(k)|}{|k|} \cdot \frac{|k|}{|h|} \leq \frac{|o_f(k)|}{|k|} \cdot C.
Since |o_f(k)|/|k| \to 0 as k \to 0, and k \to 0 as h \to 0, we conclude |o_f(k)|/|h| \to 0.
Combining these results, f(g(a+h)) = f(g(a)) + df_{g(a)}(dg_a(h)) + o(h), which shows d_a(f \circ g)(h) = df_{g(a)}(dg_a(h)). \square
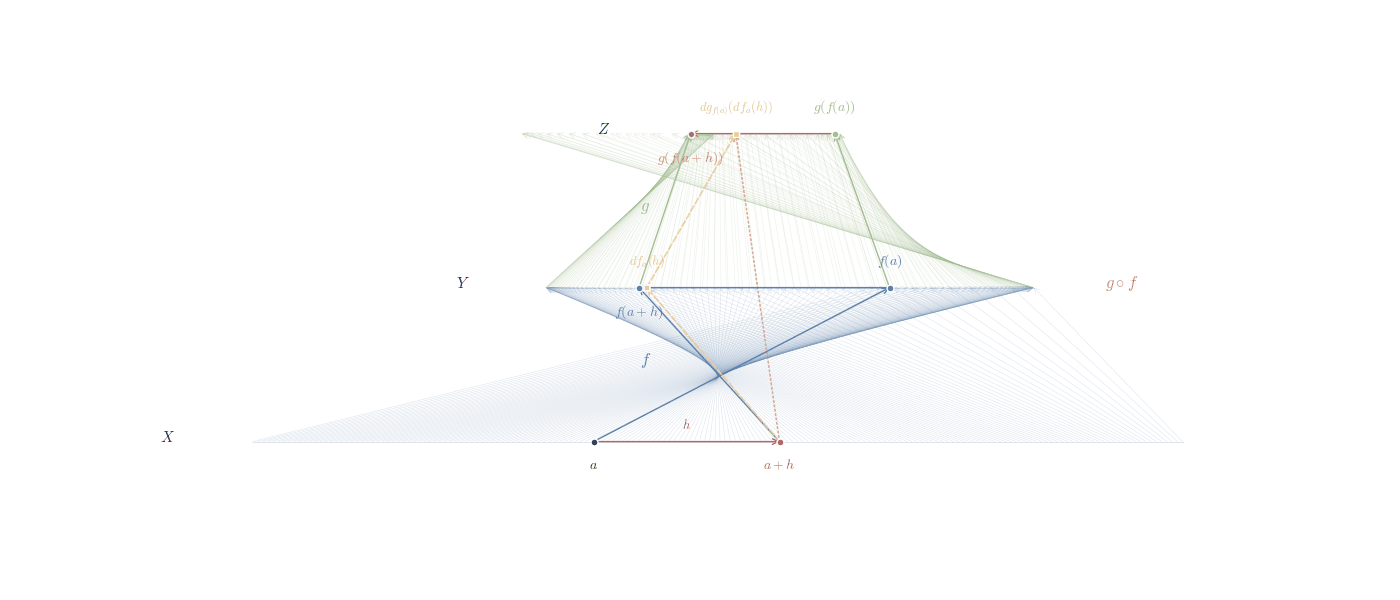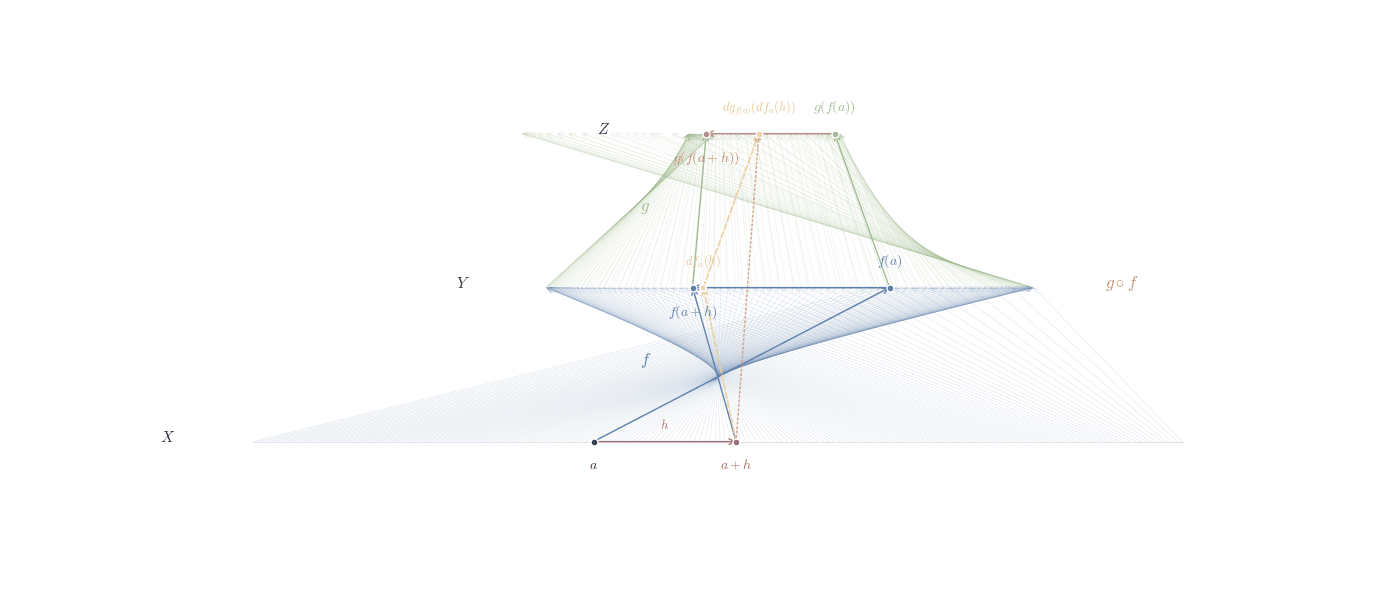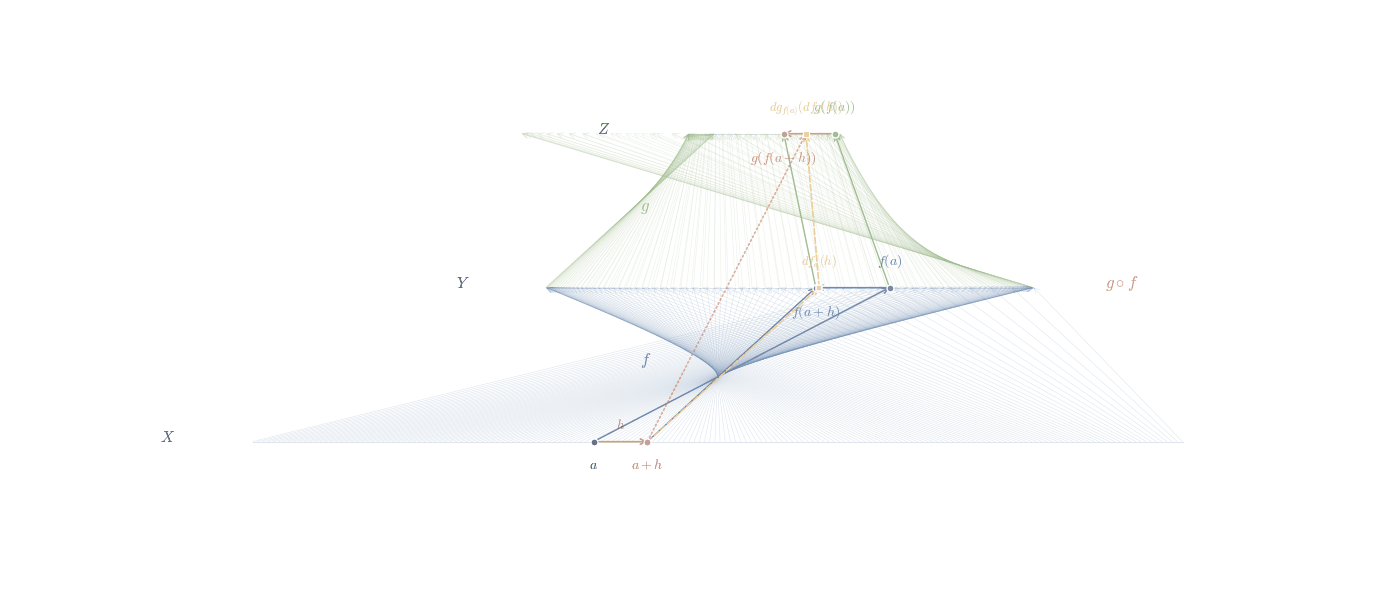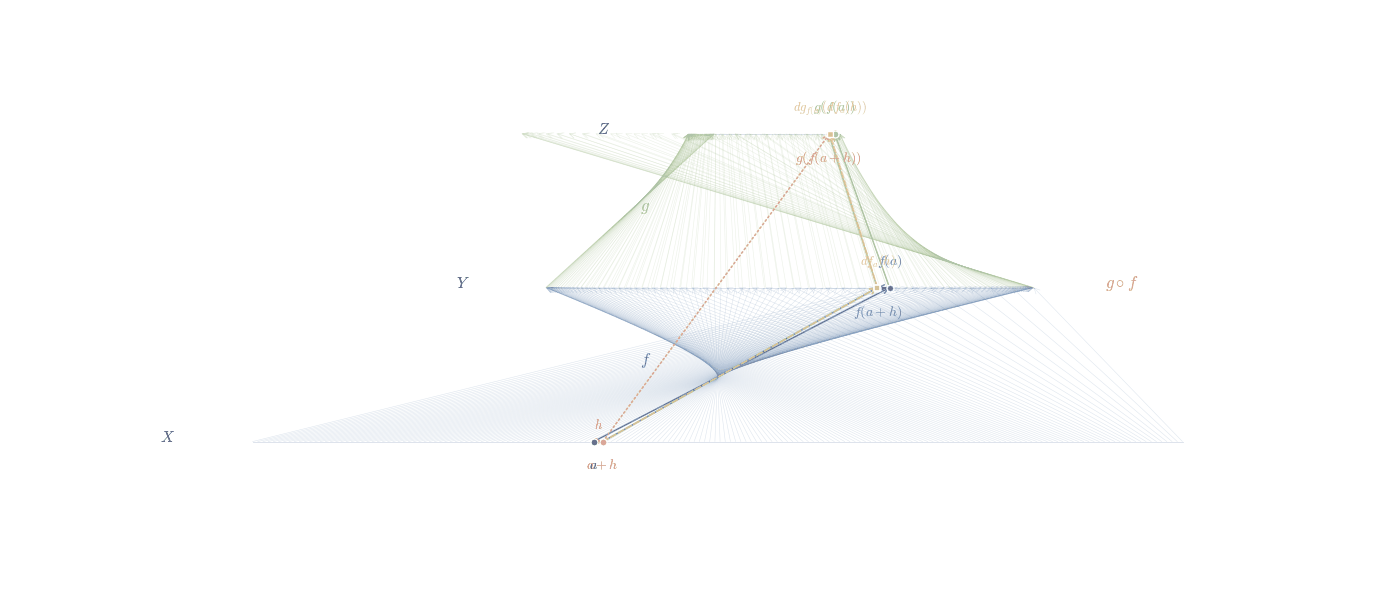
In the figure above we try to convey that the chain rule can be thought of as a way to track how changes propagate through different spaces. When a function maps one space to another, and then another function acts on this new space, the chain rule tells us how these transformations combine. It’s like sending changes through a sequence of transformations, where each step modifies the input in a way that depends on the previous step.
10.4 Why the Linear Map Perspective Matters
We have now established all the fundamental rules for differentiation. Throughout, we have emphasized viewing the differential df_a as a linear map rather than merely treating f'(a) as a number. It is time to make explicit why this perspective is not just a philosophical preference.
10.4.1 The Chain Rule is Just Composition
The chain rule states that d_a(f \circ g)(h) = df_{g(a)}(dg_a(h)).
This is not a formula derived from algebraic manipulation—it is the definition of how linear maps compose. If S: V \to W and T: W \to X are linear maps, their composition is (T \circ S)(v) = T(S(v)).
The chain rule says: differentials compose by composition of linear maps. The derivative of a composition is the composition of derivatives. Once you understand that df_a is a linear map, the chain rule becomes inevitable.
Without the linear map perspective, the formula (f \circ g)'(a) = f'(g(a)) \cdot g'(a) appears, to some, as a computational rule to memorize.
10.4.2 The Product Rule Shows the Limits of Linearity
The sum rule follows from linearity: d_a(f+g) = df_a + dg_a. One might naively expect the product rule to be similarly simple: d_a(fg) = df_a \cdot dg_a. But this is false.
As mentioned the map (f, g) \mapsto fg is bilinear, not linear. It satisfies
(cf) \cdot g = c(fg) (linear in each factor separately)
(f_1 + f_2) \cdot g = f_1 g + f_2 g (distributes over addition)
But it does not satisfy (f_1 + f_2)(g_1 + g_2) = f_1 g_1 + f_2 g_2. Multiplication mixes the two inputs.
The product rule d_a(fg) = f(a) \, dg_a + g(a) \, df_a
is the linearization of a bilinear map. When we form the differential, we fix one variable at its base value while the other varies. This gives two terms: one where f is frozen and g moves, another where g is frozen and f moves. The cross term df_a \cdot dg_a is second-order and vanishes.
10.4.3 Generalization to Higher Dimensions
In one dimension, the distinction between df_a (a linear map) and f'(a) (a scalar) seems like unnecessary abstraction. After all, a linear map \mathbb{R} \to \mathbb{R} is just multiplication by a number.
In higher dimensions:
In one dimension:
f: \mathbb{R} \to \mathbb{R}
df_a: \mathbb{R} \to \mathbb{R} is multiplication by f'(a)
One scalar encodes everything
In higher dimensions:
f: \mathbb{R}^n \to \mathbb{R}^m
df_a: \mathbb{R}^n \to \mathbb{R}^m is a linear map
f'(a) becomes an m \times n matrix (the Jacobian)
You cannot think of this as “multiplication by a number”
The chain rule becomes d_a(f \circ g) = df_{g(a)} \circ dg_a, which in coordinates is (f \circ g)'(a) = f'(g(a)) \cdot g'(a), where the dot now denotes matrix multiplication—the coordinate representation of composition of linear maps.
The linear map perspective is not pedagogical decoration. It is the only framework that extends beyond one dimension.
10.5 Quotient Rule
Quotients arise naturally when forming ratios of differentiable quantities. The quotient rule follows by reducing the problem to two solved cases: the reciprocal function x \mapsto 1/x has a known differential, and applying the product rule to f \cdot (1/g) yields the general formula. We begin by computing the differential of the reciprocal.
To see this concretely, consider a physical pendulum with angular momentum L(t) and moment of inertia I(t), both varying with time. The angular velocity \omega(t) = L(t)/I(t) is a quotient: external torques alter L while mass redistribution changes I. Computing \omega'(t) requires differentiating a ratio.
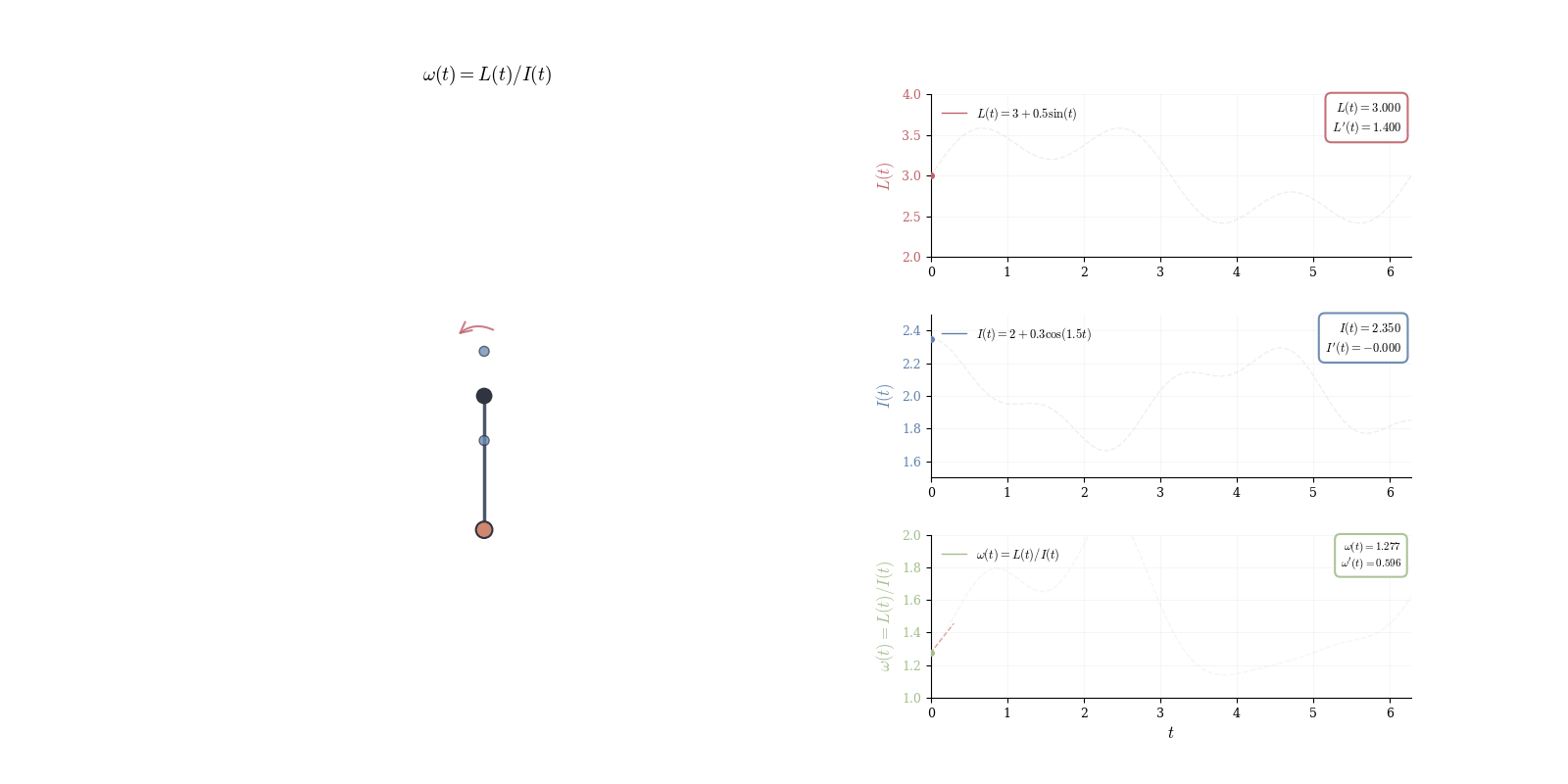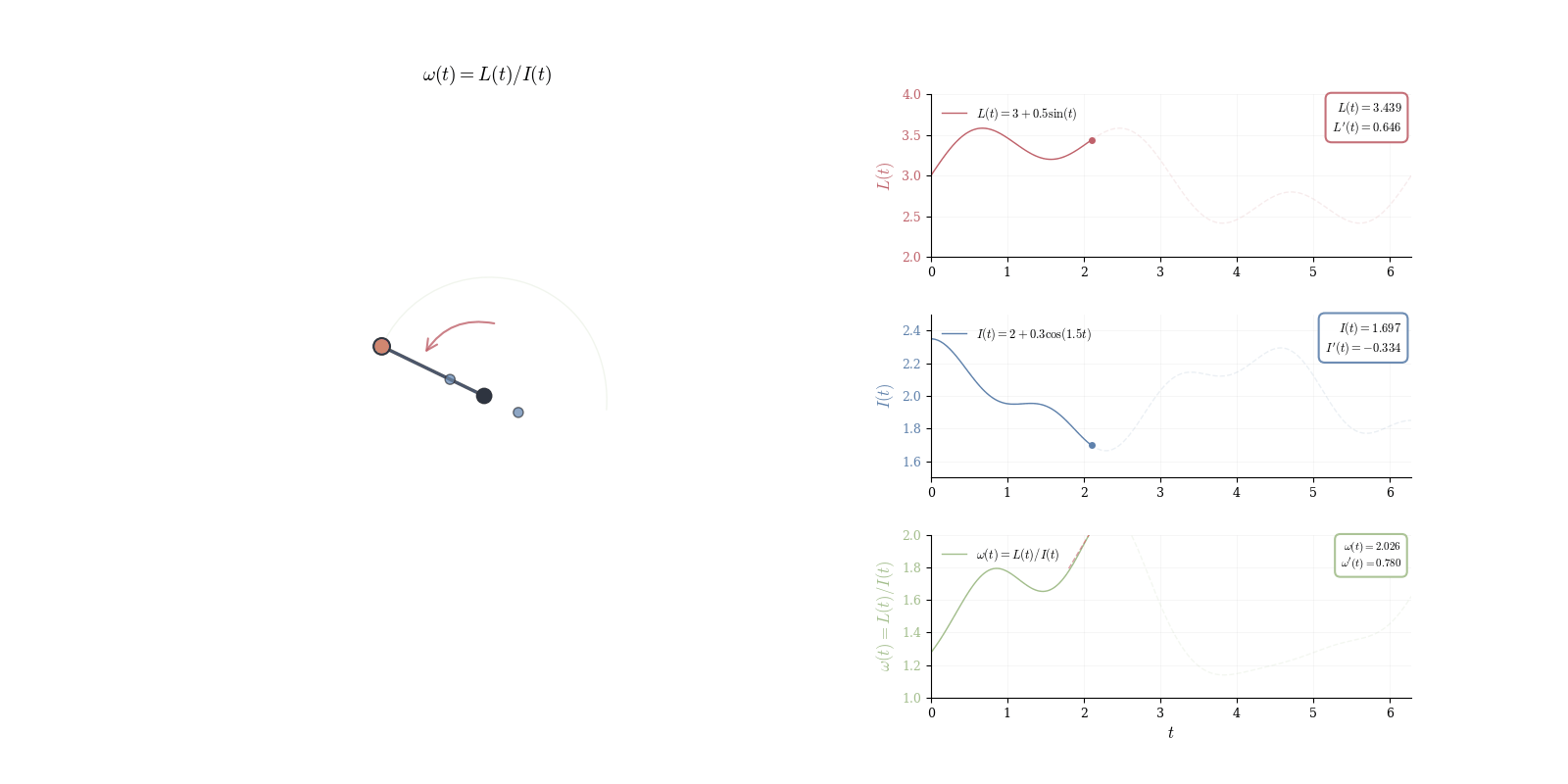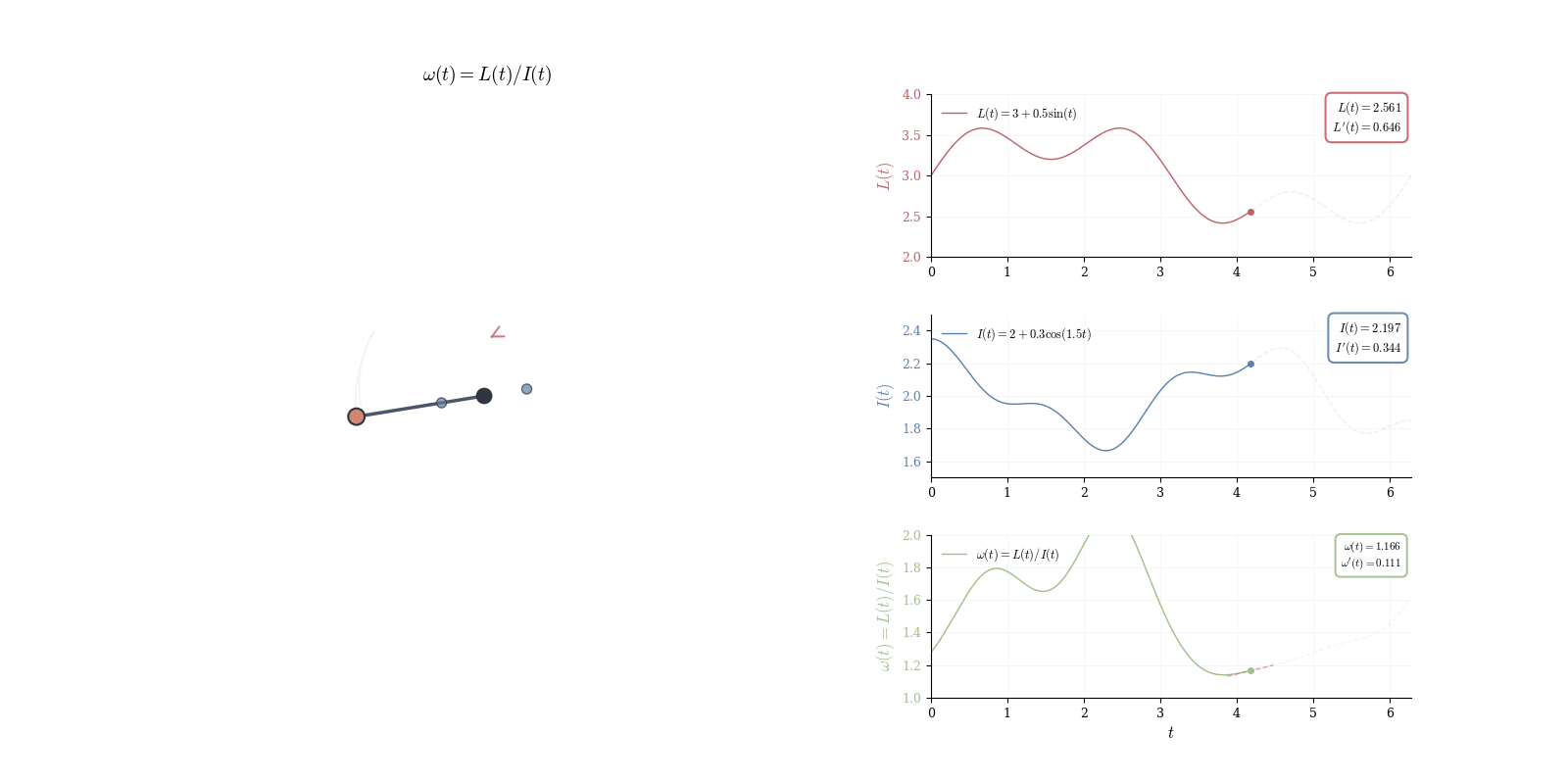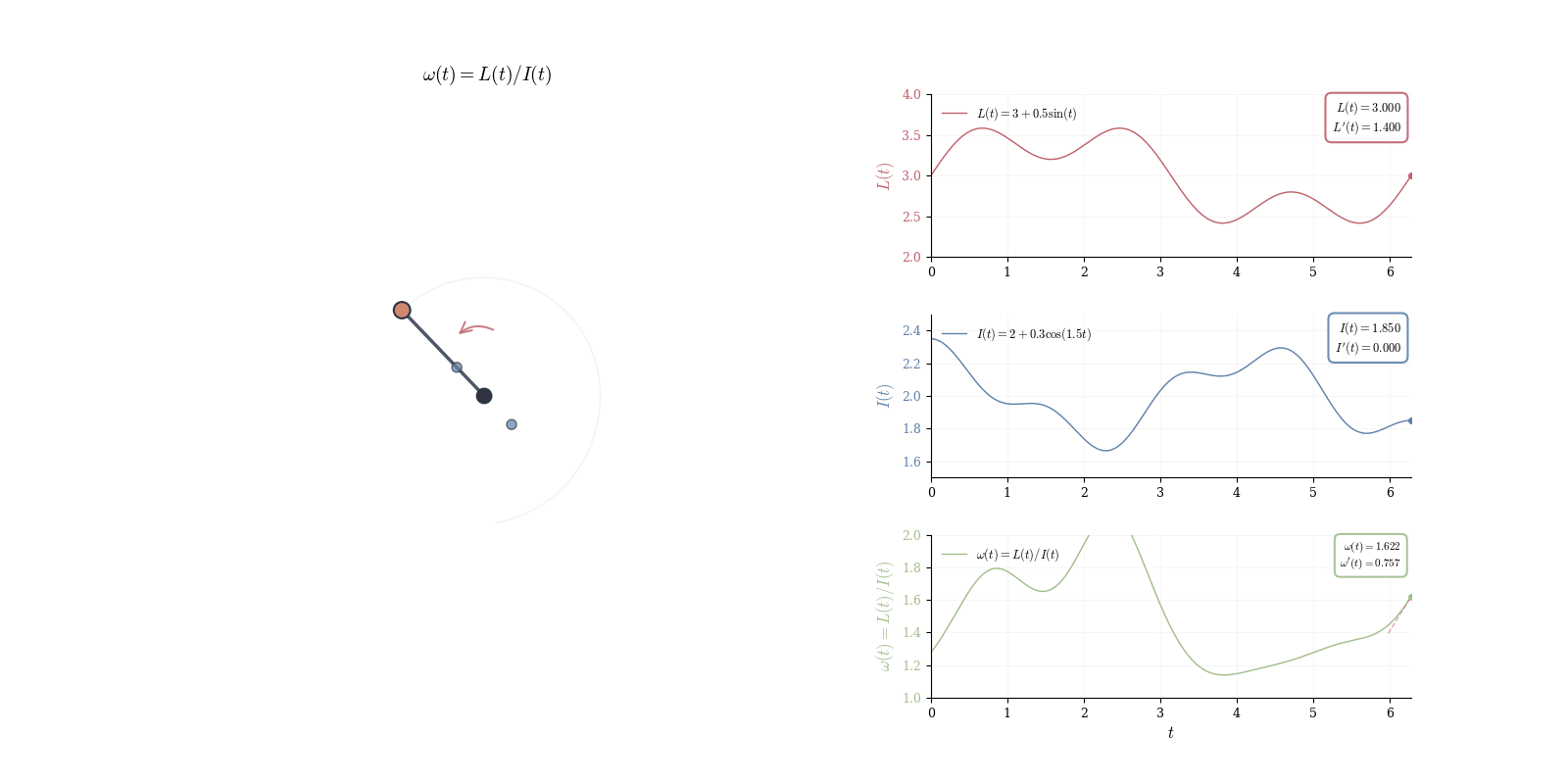
Theorem 10.6 (Differential of the Reciprocal) For \phi(x) = 1/x with x \neq 0, we have d_a\phi(h) = -\frac{h}{a^2}.
In coordinates: \left(\frac{1}{x}\right)' = -\frac{1}{x^2}.
For a \neq 0, compute \frac{\phi(a+h) - \phi(a)}{h} = \frac{\frac{1}{a+h} - \frac{1}{a}}{h} = \frac{a - (a+h)}{h \cdot a(a+h)} = \frac{-h}{h \cdot a(a+h)} = \frac{-1}{a(a+h)}.
As h \to 0, this approaches -1/a^2. Thus \phi'(a) = -1/a^2, giving the differential d_a\phi(h) = -h/a^2. \square
Theorem 10.7 (Quotient Rule) If f and g are differentiable at a with g(a) \neq 0, then f/g is differentiable at a with d_a\left(\frac{f}{g}\right)(h) = \frac{g(a) \, df_a(h) - f(a) \, dg_a(h)}{[g(a)]^2}.
In coordinates: \left(\frac{f}{g}\right)'(a) = \frac{f'(a) g(a) - f(a) g'(a)}{[g(a)]^2}.
Write f/g = f \cdot (1/g). The product rule gives d_a\left(\frac{f}{g}\right)(h) = f(a) \cdot d_a\left(\frac{1}{g}\right)(h) + \frac{1}{g(a)} \cdot df_a(h).
The composition 1/g evaluated at a gives 1/g(a), and by the chain rule, its differential is d_a\left(\frac{1}{g}\right)(h) = d_{g(a)}\phi(dg_a(h)) = -\frac{dg_a(h)}{[g(a)]^2}.
Substituting, d_a\left(\frac{f}{g}\right)(h) = f(a) \cdot \left(-\frac{dg_a(h)}{[g(a)]^2}\right) + \frac{df_a(h)}{g(a)} = \frac{g(a) \, df_a(h) - f(a) \, dg_a(h)}{[g(a)]^2}.\quad \square
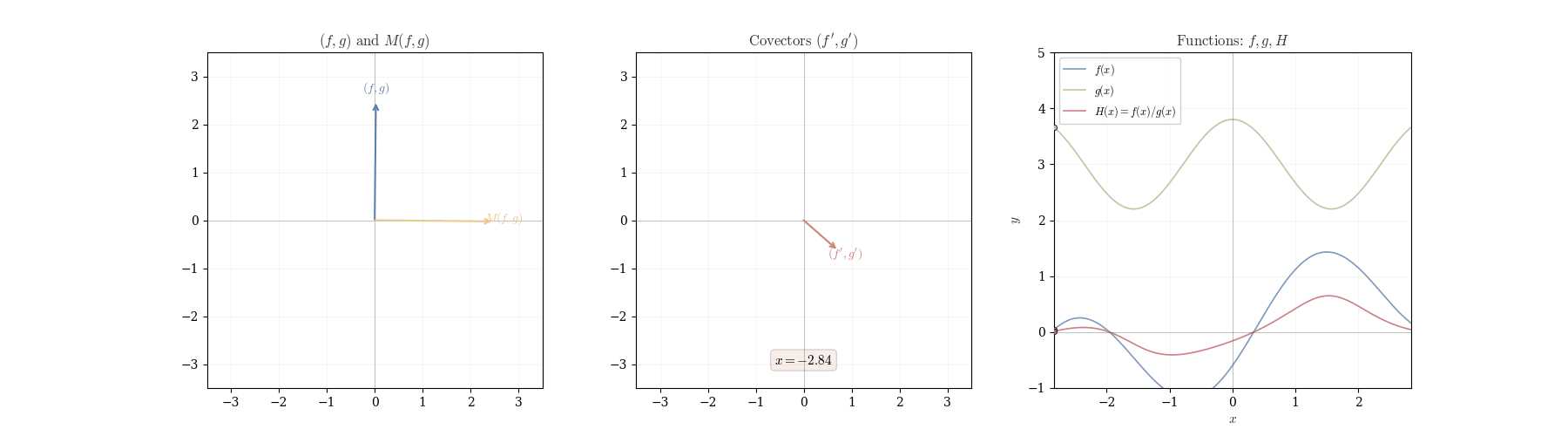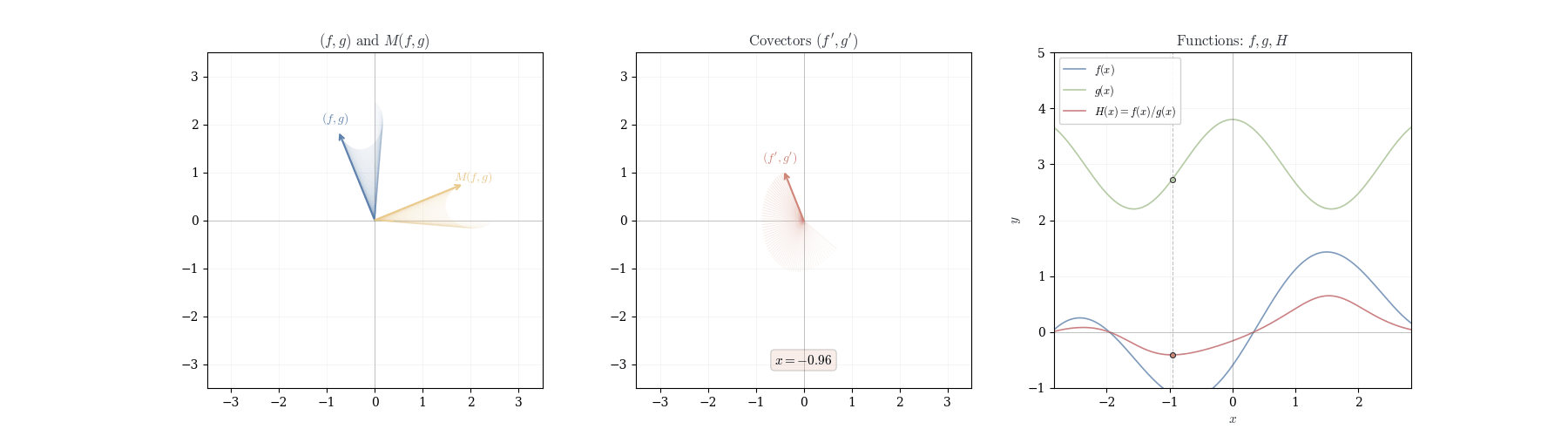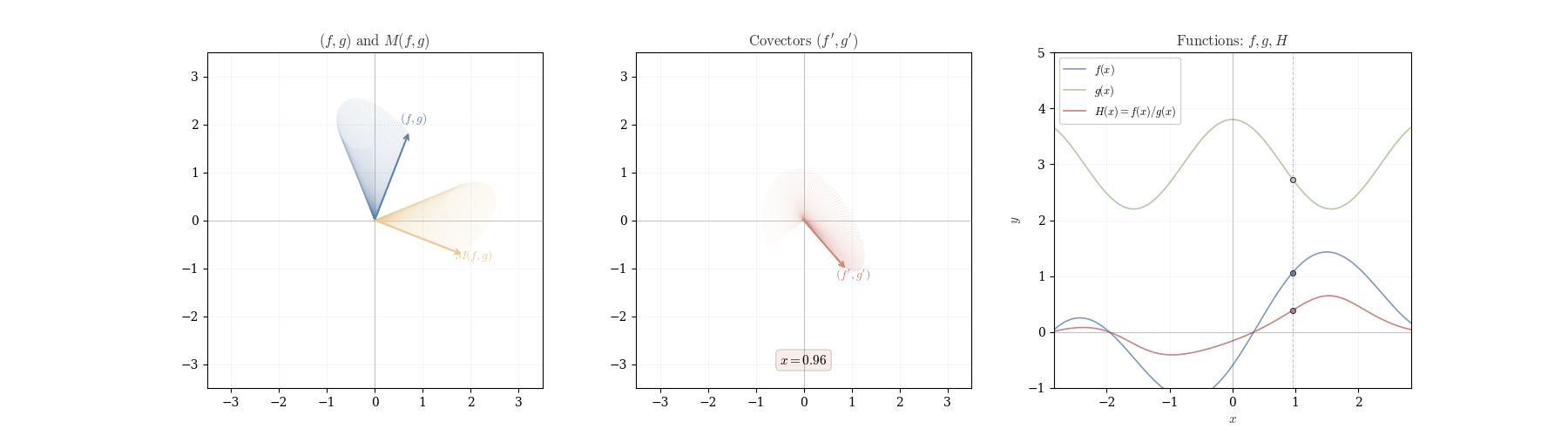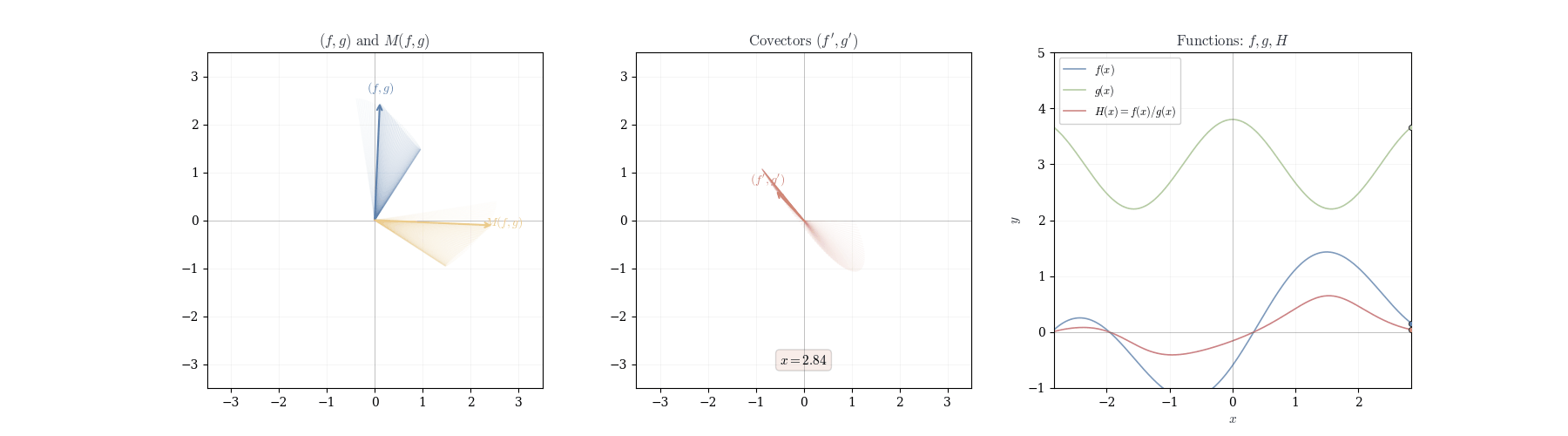
Example 10.1 (Quotient Rule Application) For f(x) = \frac{x^2}{x+1} at a = 1, we have d_1\left(\frac{x^2}{x+1}\right)(h) = \frac{2 \cdot 2h - 1 \cdot h}{4} = \frac{3h}{4}. Thus f'(1) = 3/4.
10.6 Geometric Interpretation
The product rule expresses d_a(fg) as a linear combination d_a(fg) = f(a) \cdot dg_a + g(a) \cdot df_a. This is not the product of differentials but a weighted sum. When we displace from a to a+h, both f and g change. The product changes in two ways: first, g varies while f remains fixed at f(a), contributing f(a) \cdot dg_a(h); second, f varies while g remains fixed at g(a), contributing g(a) \cdot df_a(h). The term df_a(h) \cdot dg_a(h), representing simultaneous variation, is proportional to h^2 and vanishes in the first-order approximation.
The quotient rule exhibits analogous structure with antisymmetry d_a\left(\frac{f}{g}\right) = \frac{1}{g(a)} \cdot df_a - \frac{f(a)}{[g(a)]^2} \cdot dg_a. Increasing f while holding g fixed increases the quotient, weighted by 1/g(a). Increasing g while holding f fixed decreases the quotient, weighted by -f(a)/[g(a)]^2. As g(a) \to 0, the coefficient [g(a)]^{-2} diverges: the differential becomes infinitely sensitive to perturbations in the denominator.
This antisymmetry can be encoded in a linear map. Define T: \mathbb{R}^2 \to \mathbb{R}^2 by T(x, y) = (y, -x). This swaps coordinates and negates the second. Observe that \begin{pmatrix}x&y\end{pmatrix}\,T(x,y) = xy - xy = 0—the output is orthogonal to the input. The quotient rule becomes d_a\left(\frac{f}{g}\right) = \frac{1}{[g(a)]^2} \begin{pmatrix}df_a & dg_a\end{pmatrix}\, T(f(a), g(a)). When f and g change proportionally—when df_a = \lambda dg_a—the vectors (df_a(h), dg_a(h)) and (f(a), g(a)) are parallel. After applying T, they become orthogonal, and the differential vanishes. This is why (f/g)' = 0 when f and g are scalar multiples.
These observations hint at deeper geometric ideas that appear in Einstein’s theory of general relativity.
In Einstein’s theory, spacetime is not flat—it curves in response to mass and energy. Yet physics must still make sense locally: if you zoom in on a small region of curved spacetime, it looks approximately flat, just as the surface of the Earth looks flat when you’re standing on it. This “local flatness” is precisely the idea of differentiation: we approximate a curved object by its tangent—a flat, linear approximation that works well in a small neighborhood.
The chain rule plays a central role because there is no preferred coordinate system in general relativity. One observer might describe an event using coordinates (t, x, y, z), while another uses different coordinates (t', x', y', z'). Physical laws must be independent of this choice—they must look the same to both observers. When we transform from one coordinate system to another, rates of change transform via the chain rule. The statement “physics is the same in all coordinate systems” relies fundamentally on how derivatives compose.
We will not pursue this geometric perspective further, but the reader should recognize that the linear algebra framework from earlier and the differential calculus developed here are not just computational techniques. They form the mathematical foundation for describing geometry and thus physics on curved spaces.
10.7 Problem Set
Let f(x) = x^2 + 1 and g(x) = x^3.
Compute d_1(fg) and verify that the error (fg)(1+h) - (fg)(1) - d_1(fg)(h) is o(h).
Express d_1(f \circ g) as a composition of linear maps.
Consider a particle of unit mass on the line with position x(t) and velocity v(t). Define the kinetic energy K(v) = \tfrac{1}{2}v^2 and potential energy U(x) = \tfrac{1}{2}x^2. The Hamiltonian is the composition H(t) = K(v(t)) + U(x(t)).
Compute dH/dt.
Newton’s law states (with unit mass) dv/dt = -x. Use this and dx/dt = v to show dH/dt = 0.
Define the Lagrangian as the composition \mathscr{L}(t) = K(v(t)) - U(x(t)). Compute d\mathscr{L}/dt and evaluate using the equations of motion.
(Bonus) Find the condition on x and v such that d\mathscr{L}/dt = 0. What does this condition mean physically?
At a = 1: df_1(h) = 2h, dg_1(h) = 3h, f(1) = 2, g(1) = 1. The product rule gives d_1(fg)(h) = f(1)\,dg_1(h) + g(1)\,df_1(h) = 6h + 2h = 8h. Since (fg)(x) = x^5 + x^3, we have (fg)(1+h) = 2 + 8h + 13h^2 + 11h^3 + 5h^4 + h^5. The error is E(h) = 13h^2 + 11h^3 + 5h^4 + h^5, whence |E(h)|/|h| \to 0.
By the chain rule, d_1(f \circ g)(h) = df_{g(1)}(dg_1(h)) = df_1(3h) = 6h.
By the chain rule applied to each composition, \frac{dH}{dt} = K'(v(t)) \frac{dv}{dt} + U'(x(t)) \frac{dx}{dt} = v \frac{dv}{dt} + x \frac{dx}{dt}.
Substitute dx/dt = v and dv/dt = -x: \frac{dH}{dt} = v(-x) + xv = 0. Thus H is constant on trajectories satisfying Newton’s law.
By the chain rule, \frac{d\mathscr{L}}{dt} = K'(v(t)) \frac{dv}{dt} - U'(x(t)) \frac{dx}{dt} = v \frac{dv}{dt} - x \frac{dx}{dt}. Substituting the equations of motion, \frac{d\mathscr{L}}{dt} = v(-x) - xv = -2xv. The Lagrangian is not conserved. \square
From part (c), d\mathscr{L}/dt = -2xv. The condition d\mathscr{L}/dt = 0 requires xv = 0, which holds if and only if x = 0 or v = 0. These are the turning points of the motion: the particle passes through the origin with maximum velocity (x = 0, v \neq 0), or reaches maximum displacement and momentarily stops (x \neq 0, v = 0). At these instants, kinetic and potential energies are instantaneously unchanging in their difference.