
8 Vectors and Linear Maps
8.1 Vectors and Linear Maps
Differentiation, at its core, is about linear approximation. To understand how a function changes, we replace it locally with something simpler: a linear transformation. This chapter develops the language needed to make that idea precise.
In general, a vector is an element of a space satisfying certain axioms (which we omit here). For our purposes, we adopt the physicist’s view: a vector is an arrow in space, with magnitude and direction. This geometric viewpoint suffices and keeps the discussion concrete.
Vectors may be added and scaled: if \mathbf{u} and \mathbf{v} are vectors and c is a scalar, then \mathbf{u} + \mathbf{v} and c\mathbf{v} are again vectors. These operations generate linear combinations, the fundamental tool for describing change and approximation.
We work in \mathbb{R}^2 because arrows in the plane are easy to see. But the theory applies just as well to \mathbb{R}, where “vectors” are real numbers. When we return to functions f: \mathbb{R} \to \mathbb{R}, the derivative will be a linear map on this one-dimensional space. The planar setting reveals structure that one dimension obscures.
We shall represent vectors as arrows in the plane and express them in terms of coordinates relative to a chosen basis. We shall also consider linear maps (like \lim), which are functions that preserve vector addition and scalar multiplication, and examine certain linear maps called functionals, which we will think of as measurements that assign real numbers to vectors.
8.2 Vectors and Coordinates
A vector is, first and foremost, a geometric object: an arrow in the plane with a definite magnitude and direction. Its position is typically anchored at the origin, but the vector itself is determined solely by the displacement it represents. This geometric viewpoint allows us to visualize addition, scaling, and other operations directly.
These objects follow certain algebraic rules. Formally, we can define \mathbb{R}^2 as a vector space over the real numbers (meaning it satisfies the following properties - for the interested reader we list them below)
NoteAxioms
The set \mathbb{R}^2 = \{(x,y) : x,y \in \mathbb{R}\} with vector addition and scalar multiplication is a vector space, because for any vectors \mathbf{u}, \mathbf{v}, \mathbf{w} \in \mathbb{R}^2 and scalars a, b \in \mathbb{R}, the following hold:
- Closure under addition: \mathbf{u} + \mathbf{v} \in \mathbb{R}^2
- Commutativity: \mathbf{u} + \mathbf{v} = \mathbf{v} + \mathbf{u}
- Associativity: (\mathbf{u} + \mathbf{v}) + \mathbf{w} = \mathbf{u} + (\mathbf{v} + \mathbf{w})
- Zero vector exists: there is \mathbf{0} = (0,0) with \mathbf{v} + \mathbf{0} = \mathbf{v}
- Additive inverse: for each \mathbf{v} there exists -\mathbf{v} with \mathbf{v} + (-\mathbf{v}) = \mathbf{0}
- Closure under scalar multiplication: a \mathbf{v} \in \mathbb{R}^2
- Distributivity over vector addition: a(\mathbf{u} + \mathbf{v}) = a\mathbf{u} + a\mathbf{v}
- Distributivity over scalar addition: (a + b)\mathbf{v} = a\mathbf{v} + b\mathbf{v}
- Associativity of scalars: a(b\mathbf{v}) = (ab)\mathbf{v}
- Multiplicative identity: 1 \mathbf{v} = \mathbf{v}
For our purposes, it suffices to know that if vectors are combined by addition or scaled by a real number, the result is again a vector in the same space. This property, closure under linear combinations, is fundamental to the structure of a vector space.
Definition 8.1 (Linear Combination in \mathbb{R}^2) Let \mathbf{v}_1, \dots, \mathbf{v}_n \in \mathbb{R}^2. A linear combination of \mathbf{v}_1, \dots, \mathbf{v}_n is any vector of the form
c_1 \mathbf{v}_1 + c_2 \mathbf{v}_2 + \dots + c_n \mathbf{v}_n,
where c_1, \dots, c_n \in \mathbb{R} are scalars.
The coefficients c_1, \dots, c_n are called the weights of the linear combination.
To work with vectors numerically, we need coordinates. This requires choosing a basis: a pair of reference vectors with respect to which every other vector can be uniquely decomposed. The key word is uniquely—this is what makes coordinates well-defined and what separates a basis from an arbitrary pair of vectors.

The vector \mathbf{v} itself remains fixed; what changes are the numbers we use to describe it. This is the essential tension in coordinate geometry: geometric objects are invariant, but their numerical representations depend on arbitrary choices. Linear combinations reconcile this tension: the vector is an intrinsic geometric object, but to compute with it, we decompose it relative to a basis.
Definition 8.2 (Basis of \mathbb{R}^2) A pair of vectors \mathbf{e}_1, \mathbf{e}_2 \in \mathbb{R}^2 is called a basis of \mathbb{R}^2 if every vector \mathbf{v} \in \mathbb{R}^2 can be written uniquely in the form \mathbf{v} = x \mathbf{e}_1 + y \mathbf{e}_2 for some scalars x, y \in \mathbb{R}. The scalars x and y are called the coordinates of \mathbf{v} relative to the basis (\mathbf{e}_1, \mathbf{e}_2).
Note: The uniqueness of this representation requires that \mathbf{e}_1 and \mathbf{e}_2 are linearly independent; see Definition 8.3.
8.2.0.1 Example
Let \mathbf{v} = \begin{pmatrix} 6 \\ 4 \end{pmatrix} \in \mathbb{R}^2. First, consider the standard basis \mathbf{e}_1 = \begin{pmatrix} 1 \\ 0 \end{pmatrix}, \mathbf{e}_2 = \begin{pmatrix} 0 \\ 1 \end{pmatrix}. We can write \mathbf{v} as a linear combination of the standard basis vectors \mathbf{v} = 6 \mathbf{e}_1 + 4 \mathbf{e}_2 = 6 \begin{pmatrix} 1 \\ 0 \end{pmatrix} + 4 \begin{pmatrix} 0 \\ 1 \end{pmatrix}.
Doing the algebra coordinate-wise 6 \begin{pmatrix} 1 \\ 0 \end{pmatrix} = \begin{pmatrix} 6 \\ 0 \end{pmatrix}, \quad 4 \begin{pmatrix} 0 \\ 1 \end{pmatrix} = \begin{pmatrix} 0 \\ 4 \end{pmatrix}, \begin{pmatrix} 6 \\ 0 \end{pmatrix} + \begin{pmatrix} 0 \\ 4 \end{pmatrix} = \begin{pmatrix} 6 \\ 4 \end{pmatrix}.
So the coordinates of \mathbf{v} relative to the standard basis are [\mathbf{v}]_{\mathcal{E}} = \begin{pmatrix} 6 \\ 4 \end{pmatrix}.
Now consider a different basis, say \mathcal{F} \mathbf{f}_1 = \begin{pmatrix} 2 \\ 1 \end{pmatrix}, \quad \mathbf{f}_2 = \begin{pmatrix} 1 \\ 1 \end{pmatrix}.
We seek scalars x, y such that \mathbf{v} = x \mathbf{f}_1 + y \mathbf{f}_2 = x \begin{pmatrix} 2 \\ 1 \end{pmatrix} + y \begin{pmatrix} 1 \\ 1 \end{pmatrix}.
Combine coordinates component-wise x \begin{pmatrix} 2 \\ 1 \end{pmatrix} + y \begin{pmatrix} 1 \\ 1 \end{pmatrix} = \begin{pmatrix} 2x + y \\ x + y \end{pmatrix}.
Set equal to \mathbf{v} we get 2x + y = 6 and x + y = 4. Solving the system x = 2, \quad y = 2.
So in the basis \mathcal{F}, the coordinates of \mathbf{v} are [\mathbf{v}]_{\mathcal{F}} = \begin{pmatrix} 2 \\ 2 \end{pmatrix}.
Notice that the vector \mathbf{v} itself does not change; only its coordinates relative to the chosen basis have changed. This computation also shows how we do algebra with vectors, we scale and add the coordinates of the basis vectors component-wise.
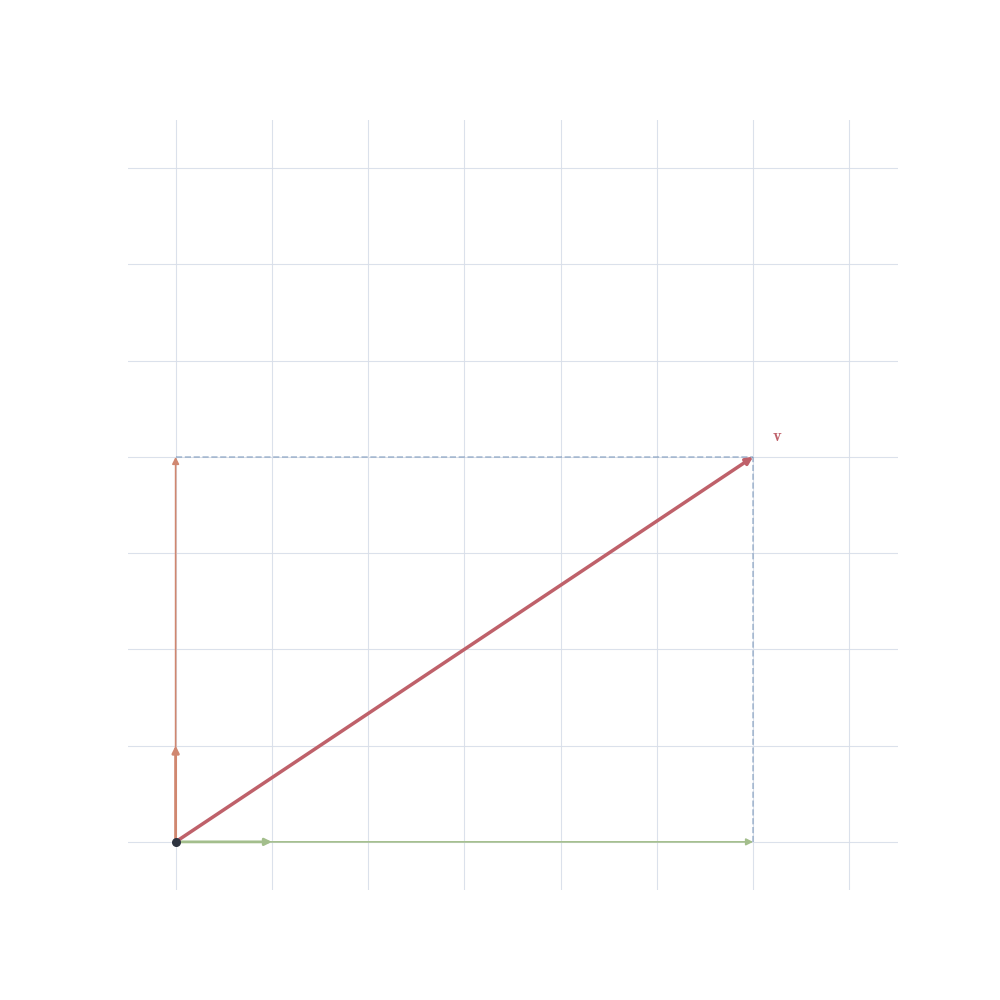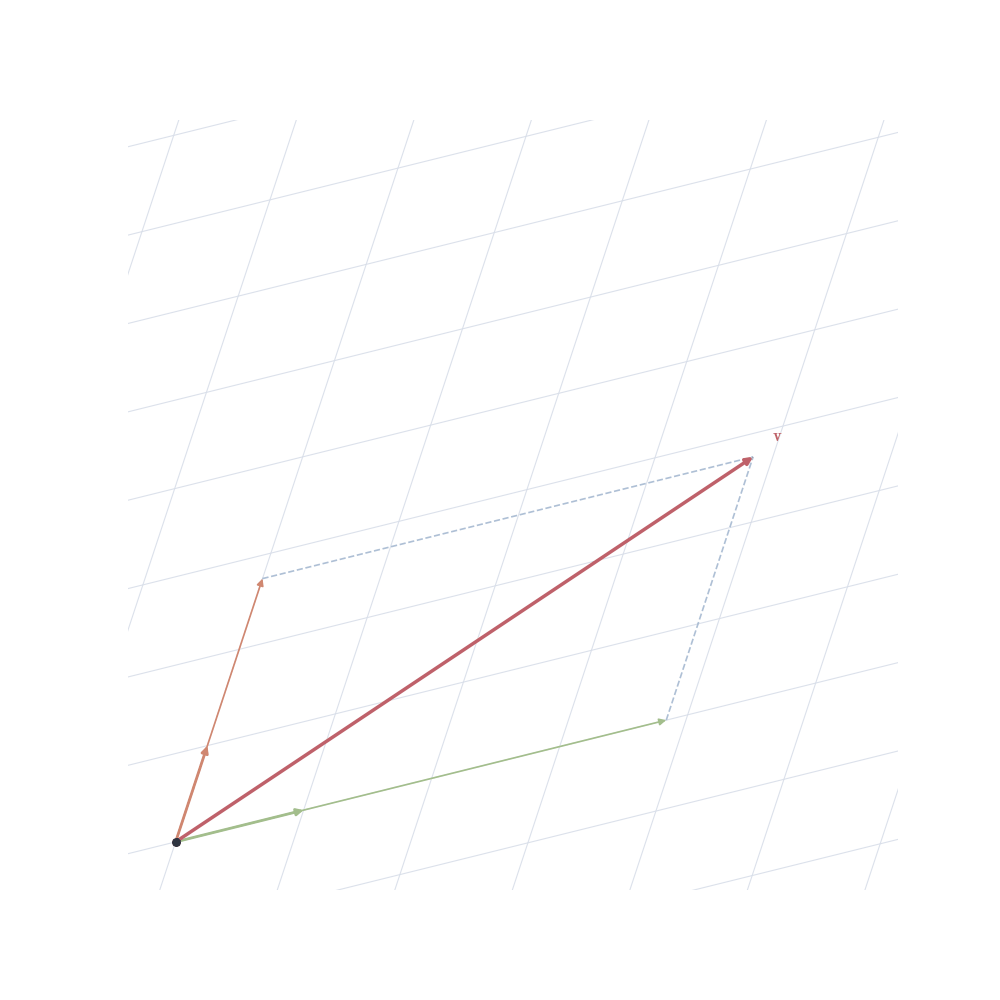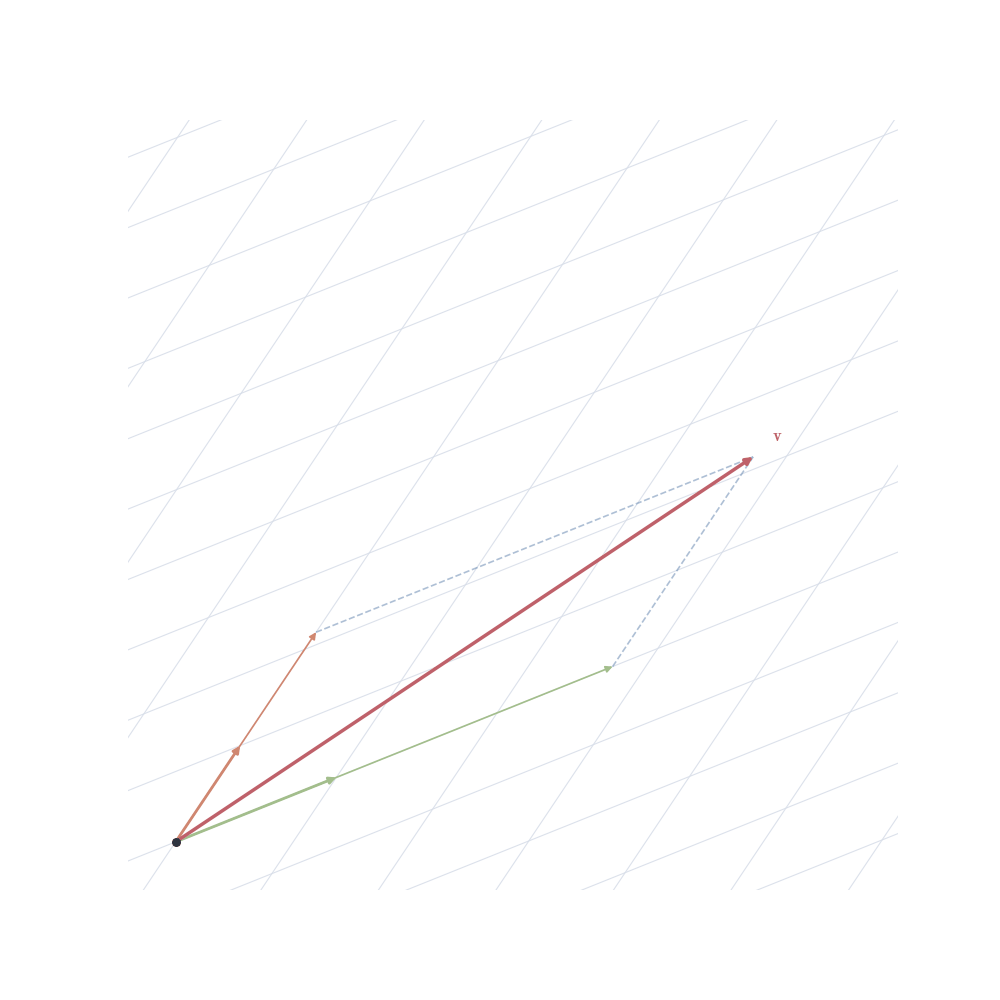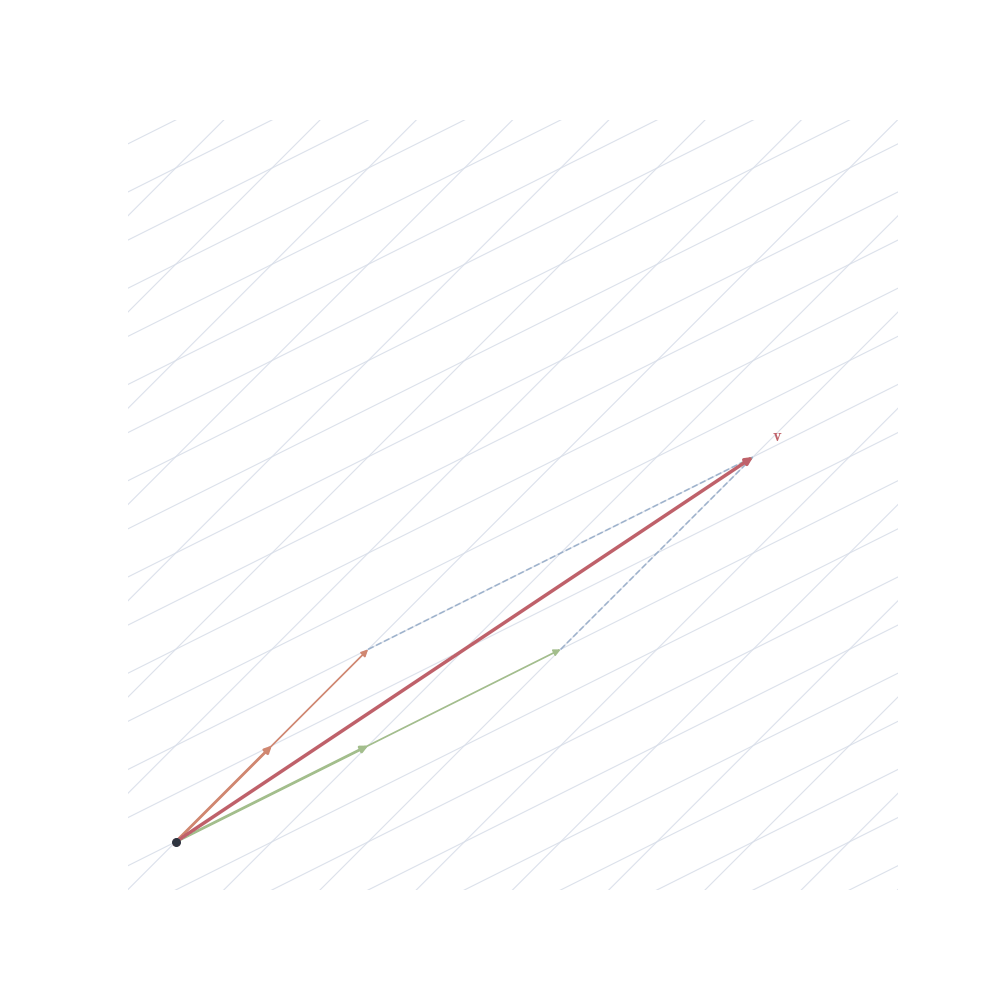
The definition of basis required uniqueness of coordinates. But what guarantees this property? If two vectors point in the same direction—one merely a scaled version of the other—then we could write the same vector as infinitely many different combinations, destroying the whole idea of coordinates. The precise condition that prevents this disaster is linear independence.
Definition 8.3 (Linear Independence) Vectors \mathbf{v}_1, \dots, \mathbf{v}_n \in \mathbb{R}^2 are linearly independent if the only way to combine them to produce \mathbf{0} is the trivial combination: c_1 \mathbf{v}_1 + c_2 \mathbf{v}_2 + \dots + c_n \mathbf{v}_n = \mathbf{0} \quad \implies \quad c_1 = c_2 = \dots = c_n = 0.
In \mathbb{R}^2, this means neither vector is a scalar multiple of the other—they point in genuinely independent directions. For \mathbb{R}, any nonzero number constitutes a basis.
The definition raises a natural question: how many linearly independent vectors can exist in \mathbb{R}^2? Since each vector is described by two coordinates, and checking linear independence amounts to solving a system of equations, we might expect a constraint. Indeed, the plane cannot accommodate infinitely many independent directions—it has only two degrees of freedom.
Theorem 8.1 (Maximum Size of Linearly Independent Sets) Any set of three or more vectors in \mathbb{R}^2 is linearly dependent. Equivalently, the maximum number of linearly independent vectors in \mathbb{R}^2 is two.
TipProof.
Let \mathbf{v}_1, \mathbf{v}_2, \mathbf{v}_3 \in \mathbb{R}^2 be arbitrary. Write \mathbf{v}_1 = \begin{pmatrix} a_1 \\ b_1 \end{pmatrix}, \quad \mathbf{v}_2 = \begin{pmatrix} a_2 \\ b_2 \end{pmatrix}, \quad \mathbf{v}_3 = \begin{pmatrix} a_3 \\ b_3 \end{pmatrix}.
We seek scalars c_1, c_2, c_3 \in \mathbb{R} such that c_1 \mathbf{v}_1 + c_2 \mathbf{v}_2 + c_3 \mathbf{v}_3 = \mathbf{0}.
Writing this in coordinates, c_1 \begin{pmatrix} a_1 \\ b_1 \end{pmatrix} + c_2 \begin{pmatrix} a_2 \\ b_2 \end{pmatrix} + c_3 \begin{pmatrix} a_3 \\ b_3 \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix}.
This yields the system \begin{cases} c_1 a_1 + c_2 a_2 + c_3 a_3 = 0 \\ c_1 b_1 + c_2 b_2 + c_3 b_3 = 0. \end{cases}
We have two equations in three unknowns. Such a system always admits a nontrivial solution. To see this, suppose a_1 \neq 0 (if all coefficients vanish, we can choose c_1 = 1 and c_2 = c_3 = 0). Solve the first equation for c_1: c_1 = -\frac{c_2 a_2 + c_3 a_3}{a_1}.
Substitute into the second equation: -\frac{c_2 a_2 + c_3 a_3}{a_1} b_1 + c_2 b_2 + c_3 b_3 = 0.
This simplifies to a single equation in c_2 and c_3. We may choose c_3 = 1 and solve for c_2, then back-substitute to find c_1. Thus a nontrivial solution exists, and the vectors are linearly dependent. \square
The result confirms what geometry suggests: the plane has exactly two independent directions. This immediately implies that any pair of linearly independent vectors must span the entire space. Otherwise, there would be a vector outside their span, and together with the original pair, we would have three independent vectors—contradicting what we just proved. This observation yields the fundamental property of bases.
Corollary 8.1 (Unique Representation by a Basis) If \mathbf{e}_1, \mathbf{e}_2 \in \mathbb{R}^2 are linearly independent, then every vector \mathbf{v} \in \mathbb{R}^2 can be written uniquely as \mathbf{v} = x \mathbf{e}_1 + y \mathbf{e}_2 for some scalars x, y \in \mathbb{R}.
TipProof.
Consider the three vectors \mathbf{v}, \mathbf{e}_1, \mathbf{e}_2. By (see Theorem 8.1), they are linearly dependent. Thus there exist scalars c_0, c_1, c_2, not all zero, such that c_0 \mathbf{v} + c_1 \mathbf{e}_1 + c_2 \mathbf{e}_2 = \mathbf{0}.
We claim c_0 \neq 0. Otherwise, c_1 \mathbf{e}_1 + c_2 \mathbf{e}_2 = \mathbf{0} with c_1 or c_2 nonzero, contradicting the linear independence of \mathbf{e}_1, \mathbf{e}_2. Thus we may solve for \mathbf{v}: \mathbf{v} = -\frac{c_1}{c_0} \mathbf{e}_1 - \frac{c_2}{c_0} \mathbf{e}_2.
Setting x = -c_1/c_0 and y = -c_2/c_0 gives the desired representation.
Suppose \mathbf{v} = x \mathbf{e}_1 + y \mathbf{e}_2 = x' \mathbf{e}_1 + y' \mathbf{e}_2. Then (x - x') \mathbf{e}_1 + (y - y') \mathbf{e}_2 = \mathbf{0}.
By linear independence, x - x' = 0 and y - y' = 0, so x = x' and y = y'. \square
WarningSolutions
- Take \mathbf{v}_1 = \begin{pmatrix} x_1 \\ m x_1 \end{pmatrix} and \mathbf{v}_2 = \begin{pmatrix} x_2 \\ m x_2 \end{pmatrix}. Then
\mathbf{v}_1 + \mathbf{v}_2 = \begin{pmatrix} x_1 + x_2 \\ m x_1 + m x_2 \end{pmatrix} = \begin{pmatrix} x_1 + x_2 \\ m (x_1 + x_2) \end{pmatrix},
which is of the same form. For any scalar c,
c \mathbf{v}_1 = \begin{pmatrix} c x_1 \\ c m x_1 \end{pmatrix} = \begin{pmatrix} c x_1 \\ m (c x_1) \end{pmatrix},
also lies on the line. The zero vector \mathbf{0} belongs, and each \mathbf{v} has an additive inverse -\mathbf{v}. Hence all vector space axioms are satisfied.
\mathbf{v}_1 + \mathbf{v}_2 = \begin{pmatrix} 2 - 1 \\ 4 - 2 \end{pmatrix} = \begin{pmatrix} 1 \\ 2 \end{pmatrix}. This satisfies y = 2x, confirming closure under addition.
c \mathbf{v}_1 = -3 \begin{pmatrix} 1 \\ 2 \end{pmatrix} = \begin{pmatrix} -3 \\ -6 \end{pmatrix}, which also satisfies y = 2x. Thus the set is closed under scalar multiplication.
Any vector on the line y = -\frac{1}{2} x can be written as a scalar multiple of \mathbf{b} = \begin{pmatrix} 2 \\ -1 \end{pmatrix}, a convenient basis vector. Then
\mathbf{v} = \begin{pmatrix} 4 \\ -2 \end{pmatrix} = 2 \begin{pmatrix} 2 \\ -1 \end{pmatrix}.
- Let \mathbf{v} = c_1 \begin{pmatrix} 1 \\ 1 \end{pmatrix} + c_2 \begin{pmatrix} 1 \\ -1 \end{pmatrix}. Then
c_1 + c_2 = 3, \quad c_1 - c_2 = 1.
Solving gives c_1 = 2, c_2 = 1. Hence
\mathbf{v} = 2 \begin{pmatrix} 1 \\ 1 \end{pmatrix} + 1 \begin{pmatrix} 1 \\ -1 \end{pmatrix}.
8.3 Linear Maps
A linear map transforms vectors while preserving the algebraic structure: sums map to sums, and scalar multiples map to scalar multiples. Geometrically, think of rotations, reflections, scalings, shears—transformations that move every vector according to a uniform rule.
Crucially, a linear map actually transforms vectors. A rotation by 90° takes \mathbf{e}_1 = \begin{pmatrix} 1 \\ 0 \end{pmatrix} to \begin{pmatrix} 0 \\ 1 \end{pmatrix}. The vector moves. This is not the same as changing coordinates, where the geometric arrow stays fixed but its numerical description changes.
In one dimension, the structure simplifies dramatically. A linear map T: \mathbb{R} \to \mathbb{R} is just multiplication: T(x) = ax. This is what the derivative does—it’s the scalar f'(a) that best approximates how f acts near a.
Definition 8.4 (Linear Map in \mathbb{R}^2) A map T : \mathbb{R}^2 \to \mathbb{R}^2 is linear if for all \mathbf{u}, \mathbf{v} \in \mathbb{R}^2 and all scalars c \in \mathbb{R},
T(\mathbf{u} + \mathbf{v}) = T(\mathbf{u}) + T(\mathbf{v}), \qquad T(c \mathbf{v}) = c \, T(\mathbf{v}).
The linearity conditions are powerful. By choosing particular values of \mathbf{v} and c, we can derive non-trivial consequences. For instance, what happens at the origin?
Theorem 8.2 (Linear Maps Preserve Zero) If T : \mathbb{R}^2 \to \mathbb{R}^2 is linear, then T(\mathbf{0}) = \mathbf{0}.
TipProof.
Observe that T(\mathbf{0})= T(0 \cdot \mathbf{v}) = 0 \cdot T(\mathbf{v}) = \mathbf{0}. \quad\square
A linear map is determined by its action on a basis. Write \mathbf{v} = c_1 \mathbf{e}_1 + c_2 \mathbf{e}_2. Then T(\mathbf{v}) = c_1 T(\mathbf{e}_1) + c_2 T(\mathbf{e}_2). Knowing where the basis vectors go tells you where every vector goes. This is why we can represent linear maps by matrices, though we won’t pursue that here.
Remark: If T, S : \mathbb{R}^2 \to \mathbb{R}^2 are linear maps, then their sum (T + S)(\mathbf{v}) := T(\mathbf{v}) + S(\mathbf{v}) and difference (T - S)(\mathbf{v}) := T(\mathbf{v}) - S(\mathbf{v}) are also linear maps. This follows immediately from the definition of linearity by checking that (T \pm S) preserves addition and scalar multiplication.
8.4 Composition of Linear Maps
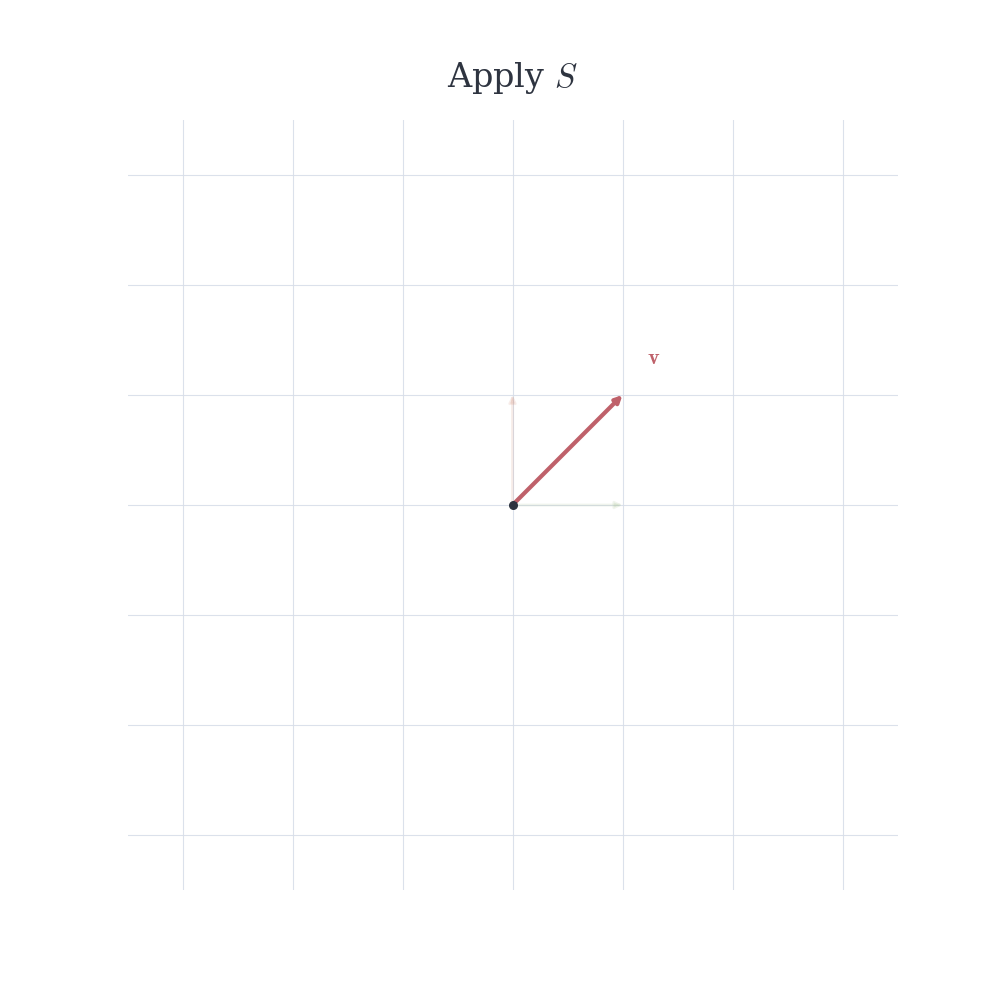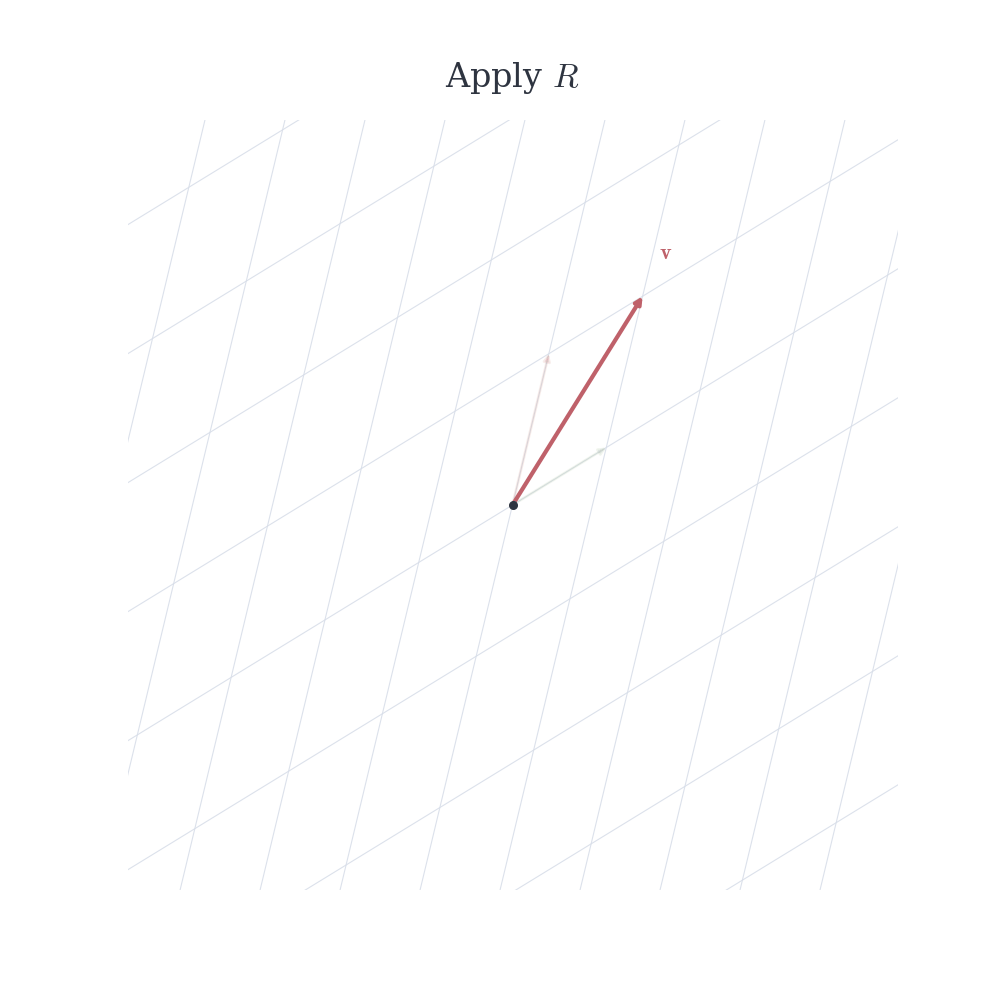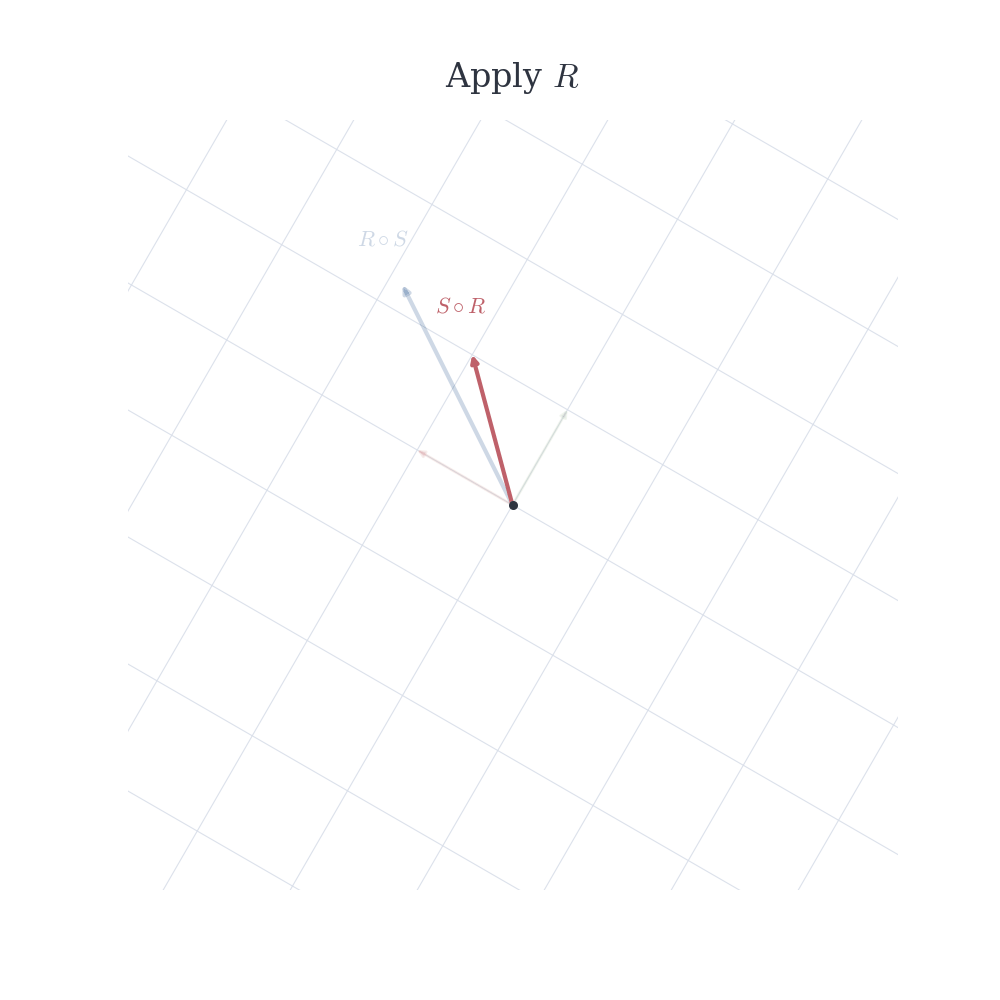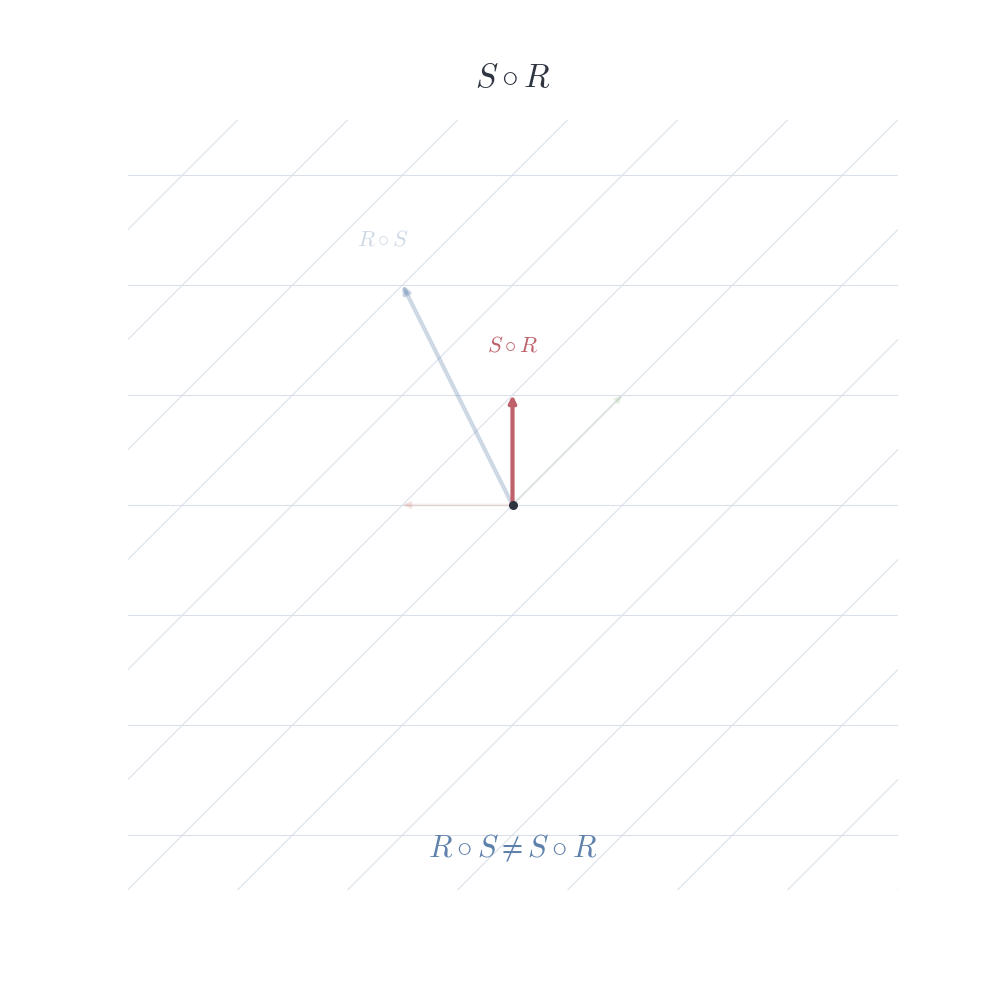
Consider two transformations of the plane. One rotates vectors, the other reflects across a line. If we apply the rotation first and then the reflection, we obtain a certain transformation. Reversing the order typically produces a different result. Composing linear maps is exactly this process: applying one linear transformation after another. Geometrically, it is natural to expect that combining two operations that preserve vector addition and scaling should again produce a map that preserves these properties.
Theorem 8.3 (Linearity of Composition) Let S, T : \mathbb{R}^2 \to \mathbb{R}^2 be linear maps. Then the composition T \circ S, defined by (T \circ S)(\mathbf{v}) = T(S(\mathbf{v})), is also linear. That is, for all \mathbf{u}, \mathbf{v} \in \mathbb{R}^2 and all scalars c \in \mathbb{R},
(T \circ S)(\mathbf{u} + \mathbf{v}) = (T \circ S)(\mathbf{u}) + (T \circ S)(\mathbf{v}), \qquad (T \circ S)(c \mathbf{v}) = c (T \circ S)(\mathbf{v}).
In general, T \circ S \neq S \circ T.
TipProof.
Take \mathbf{u}, \mathbf{v} \in \mathbb{R}^2 and c \in \mathbb{R}. Using linearity of S and T,
\begin{aligned} (T \circ S)(\mathbf{u} + \mathbf{v}) &= T(S(\mathbf{u} + \mathbf{v})) \\ &= T(S(\mathbf{u}) + S(\mathbf{v})) \\ &= T(S(\mathbf{u})) + T(S(\mathbf{v})) \\ &= (T \circ S)(\mathbf{u}) + (T \circ S)(\mathbf{v}), \end{aligned}
and clearly,
(T \circ S)(c \mathbf{v}) = T(S(c \mathbf{v})) = T(c S(\mathbf{v})) = c T(S(\mathbf{v})) = c (T \circ S)(\mathbf{v}),
as required. \square
As expected, the composition of two linear maps is linear. Yet there is no reason for the order to be irrelevant. In \mathbb{R}^2, a rotation followed by a reflection produces a transformation that is generally distinct from the reflection followed by the rotation. Linearity ensures the vector space structure is preserved, but imposes no commutativity; the geometry of the operations remains sensitive to their sequence.
WarningSolutions
- By linearity,
T(3 \mathbf{e}_1 + 2 \mathbf{e}_2) = T(3\mathbf{e}_1) + T(2\mathbf{e}_2) = 3 \mathbf{f}_1 + 2 \mathbf{f}_2.
- Compute,
\begin{align*} T(\mathbf{v}) &= 4 T(\mathbf{e}_1) + 2 T(\mathbf{e}_2) \\ &= 4(2 \mathbf{e}_1) + 2(\mathbf{e}_1 + \mathbf{e}_2) \\ &= 10 \mathbf{e}_1 + 2 \mathbf{e}_2. \end{align*}
- Let T(\mathbf{v}) = c \mathbf{v} + \mathbf{b}. Then
T(\mathbf{0}) = c\, \mathbf{0} + \mathbf{b} = \mathbf{b}.
Hence T fails to send zero to zero; it is not linear. \square
Compute, \begin{align*} S(\mathbf{v}) &= 2 S(\mathbf{e}_1) + 3 S(\mathbf{e}_2) \\ &= 2(3 \mathbf{e}_1 - \mathbf{e}_2) + 3(\mathbf{e}_1 + 2\mathbf{e}_2) \\ &= 9 \mathbf{e}_1 + 4 \mathbf{e}_2. \end{align*}
Compute, \begin{align*} U(\mathbf{v}) &= 2 U(\mathbf{e}_1) - U(\mathbf{e}_2) \\ &= 2(\mathbf{e}_1 + \mathbf{e}_2) - (2 \mathbf{e}_1 - \mathbf{e}_2) \\ &= 3 \mathbf{e}_2. \end{align*}
8.5 Linear Functionals
A linear map T : \mathbb{R}^2 \to \mathbb{R}^2 transforms vectors into vectors. A linear functional does something different: it transforms vectors into numbers. Think of it as a measurement—it assigns a scalar value to each displacement.
The terminology varies by field. Physicists call them covectors, mathematicians say linear functionals or dual vectors. The notation varies too: sometimes row vectors, sometimes differential forms. But the idea is the same: an object living in the dual space that acts on vectors to produce scalars.
In one dimension, this distinction evaporates. Vectors and functionals are both just real numbers, and the dual space coincides with the original space. When we study f: \mathbb{R} \to \mathbb{R}, the differential df_a is a functional taking displacement h to approximate change f'(a) \cdot h. Working in two dimensions makes the geometric structure visible.
Definition 8.5 (Linear Functional) A map \varphi : \mathbb{R}^2 \to \mathbb{R} is a linear functional if, for all vectors \mathbf{u}, \mathbf{v} and scalar c, \varphi(\mathbf{u} + \mathbf{v}) = \varphi(\mathbf{u}) + \varphi(\mathbf{v}), \qquad \varphi(c \mathbf{v}) = c \, \varphi(\mathbf{v}).
The geometric difference is fundamental. A vector is a displacement. A functional is an instrument for measuring displacements. When \varphi acts on \mathbf{v}, it extracts a number—how much \mathbf{v} aligns with a particular direction, how far it extends along a chosen axis.

Concretely: let \mathbf{v} = x \mathbf{e}_1 + y \mathbf{e}_2. A functional \varphi is determined by what it does to the basis:
\varphi(\mathbf{e}_1) = a, \qquad \varphi(\mathbf{e}_2) = b. Linearity forces \varphi(\mathbf{v}) = xa + yb. This is a weighted sum of coordinates—a single number encoding how \mathbf{v} looks from the perspective of \varphi. Geometrically, \varphi partitions the plane into level sets—lines where \varphi is constant. Vectors along such lines contribute nothing to the measurement. This is the intuition behind df: the differential measures change, vanishing on tangent vectors to level curves.
We can make the relationship between vectors and functionals more concrete by thinking about coordinates. Vectors are naturally written as columns. Functionals, which produce numbers by combining coordinates, are naturally written as rows
\varphi = \begin{pmatrix} a & b \end{pmatrix}, \qquad \mathbf{v} = \begin{pmatrix} x \\ y \end{pmatrix}, \qquad \varphi(\mathbf{v}) = \begin{pmatrix} a & b \end{pmatrix} \begin{pmatrix} x \\ y \end{pmatrix} = a x + b y.
This is the simplest way to see how a functional “acts” on a vector. It sums up the contributions of each component of the vector according to the functional’s own weights. The notation with rows and columns is not meant to introduce matrices formally; it is simply a convenient way to visualize the input-output relationship.
Vectors and functionals behave differently when we change the basis. The coordinates of a vector adjust so the arrow itself remains fixed. The coordinates of a functional adjust in the opposite way so that the numbers it produces remain the same.
Example 8.1 (Linear Functional) Consider the map L:\mathbb{R}^2\to\mathbb{R},\qquad L\begin{pmatrix} x\\ y \end{pmatrix}=3x-2y. This is a linear functional: it “measures’’ a vector by projecting it onto the direction (3,-2) and scaling. For a displacement vector \mathbf{h}=\begin{pmatrix} h_1 \\ h_2 \end{pmatrix}, the value L(\mathbf{h}) represents the signed change one would see if movement in the plane were observed through that directional lens.
Example 8.2 (Temperature Gradient) Consider temperature T(x,y) in a room. At point \mathbf{p} = (x_0, y_0), the differential dT_{\mathbf{p}} is a linear functional measuring how temperature changes as you move in direction \mathbf{h}.
If T(x,y) = 20 + 2x - 3y (warming eastward, cooling northward), then dT_{\mathbf{p}}(\mathbf{h}) = 2h_1 - 3h_2. Move east one meter: \mathbf{h} = \begin{pmatrix} 1 \\ 0 \end{pmatrix} gives dT_{\mathbf{p}}(\mathbf{h}) = 2 degrees. Move north: \mathbf{h} = \begin{pmatrix} 0 \\ 1 \end{pmatrix} gives -3 degrees.
This is the differential. It’s a linear functional at a point, extracting directional derivatives from displacement vectors. When we formalize derivatives, this picture guides everything.
8.5.1 Coordinate Projections
We’ve seen that any vector in \mathbb{R}^2 is written uniquely as \begin{pmatrix} x \\ y \end{pmatrix}, so it is natural to consider the maps that extract each coordinate. These maps provide the simplest examples of linear functionals on \mathbb{R}^2 and serve as the basic reference against which other functionals can be compared.
Theorem 8.4 (Coordinate Projections are Linear Functionals) The maps \pi_1, \pi_2 : \mathbb{R}^2 \to \mathbb{R} defined by \pi_1\begin{pmatrix} x \\ y \end{pmatrix} = x, \qquad \pi_2\begin{pmatrix} x \\ y \end{pmatrix} = y are linear functionals.
TipProof.
Direct computation shows that \pi_1(\mathbf{u}+\mathbf{v}) =\pi_1\begin{pmatrix}u_1+v_1\\ u_2+v_2\end{pmatrix} =u_1+v_1 =\pi_1(\mathbf{u})+\pi_1(\mathbf{v}), and similarly for scalar multiplication. The same argument applies to \pi_2. \square
Why are these coordinate projections significant? They form the simplest possible linear functionals, yet they are universal: any other functional is built from them. Just as a basis for vectors allows every vector to be written uniquely as a linear combination of basis elements, the coordinate projections serve as a “basis” for functionals.
Remark. These maps coincide with the dual basis functionals \varphi_1 and \varphi_2 corresponding to the standard basis of \mathbb{R}^2. Consequently, every linear functional on \mathbb{R}^2 can be written in the form a\,\pi_1 + b\,\pi_2.
8.6 The Euclidean Norm
Recall that in \mathbb{R} (see Section 3.1.1) we measured distance between points using d(p,q) = |p-q|. For vectors in \mathbb{R}^2, we need an analogous notion of length.
Definition 8.6 (Euclidean Norm) The Euclidean norm (or length) of \mathbf{v} = \begin{pmatrix} x \\ y \end{pmatrix} \in \mathbb{R}^2 is \|\mathbf{v}\| = \sqrt{x^2 + y^2}.
Geometrically, this is the length of the arrow from the origin to the point (x,y), given by the Pythagorean theorem.
For all \mathbf{u}, \mathbf{v} \in \mathbb{R}^2 and c \in \mathbb{R}
- Positive definiteness: \|\mathbf{v}\| \geq 0, with equality iff \mathbf{v} = \mathbf{0}
- Homogeneity: \|c\mathbf{v}\| = |c| \|\mathbf{v}\|
- Triangle inequality: \|\mathbf{u} + \mathbf{v}\| \leq \|\mathbf{u}\| + \|\mathbf{v}\|
The norm induces a metric on \mathbb{R}^2 via d(\mathbf{u}, \mathbf{v}) = \|\mathbf{u} - \mathbf{v}\|, extending our notion of distance from \mathbb{R} to the plane.
We assert that the norm is continuous; this is reasonable since “small changes in a vector should change its length only slightly,” we prove this formally
Theorem 8.5 (Continuity of the Norm) The map |\cdot|\colon\mathbb{R}^2\to\mathbb{R} is continuous. Equivalently, if \mathbf{v}_n\to\mathbf{v} in \mathbb{R}^2, then |\mathbf{v}_n|\to|\mathbf{v}| in \mathbb{R}.
TipProof.
We begin by proving the reverse triangle inequality, for all \mathbf{u},\mathbf{v}\in\mathbb{R}^2,
\bigl||\mathbf{u}|-|\mathbf{v}|\bigr|\le |\mathbf{u}-\mathbf{v}|.
Indeed, by the triangle inequality,
|\mathbf{u}|=|\mathbf{u}-\mathbf{v}+\mathbf{v}| \le |\mathbf{u}-\mathbf{v}|+|\mathbf{v}|,
so |\mathbf{u}|-|\mathbf{v}|\le |\mathbf{u}-\mathbf{v}|. Interchanging \mathbf{u} and \mathbf{v} yields
|\mathbf{v}|-|\mathbf{u}|\le |\mathbf{v}-\mathbf{u}|=|\mathbf{u}-\mathbf{v}|.
Combining both inequalities proves the claim.
Now let \mathbf{v}_n\to\mathbf{v}. Then for any \varepsilon>0, there exists N such that
|\mathbf{v}_n-\mathbf{v}|<\varepsilon \quad\text{whenever } n\ge N.
Applying the reverse triangle inequality,
\bigl||\mathbf{v}_n|-|\mathbf{v}|\bigr|\le |\mathbf{v}_n-\mathbf{v}|<\varepsilon.
Hence |\mathbf{v}_n|\to|\mathbf{v}|, as required. \square
8.7 Why This Detour? A Note to the Reader
If the connection between vectors, linear maps, and calculus isn’t immediately apparent, that’s understandable. We’ve spent considerable time developing geometric and algebraic machinery that might seem distant from the familiar task of finding tangent lines or computing rates of change.
The central insight is this, every differentiable function can be approximated, near any point, by a linear map. The derivative is not just a number (a “slope”)—it is the unique linear transformation that provides the best local approximation to the function. In one dimension, this linear map happens to be multiplication by a scalar, which we call f'(a). But the underlying structure is geometric, we are replacing a curve with its tangent line, a nonlinear object with a linear one.
By understanding what linear maps are—how they preserve addition and scaling, how they transform the plane, how they compose—we gain the conceptual tools to see differentiation as a fundamentally geometric process. In future studies, when moving to functions f : \mathbb{R}^n \to \mathbb{R}^m, the derivative becomes a matrix (the Jacobian), and the linear approximation becomes a map between vector spaces. The formalism we’ve developed here scales naturally to that setting.
Linear functionals, which may have seemed abstract, are precisely the objects that measure how a function changes in various directions. The differential df at a point is a linear functional that takes a displacement vector and returns the approximate change in f. Understanding functionals as “measurements” rather than as rows of numbers makes this geometric picture clear.
8.7.1 Theory for Its Own Sake
Beyond its utility for calculus, linear algebra is worth studying for its own sake. The interplay between geometric intuition (vectors as arrows, transformations as deformations of space) and algebraic structure (bases, coordinates, linear combinations) is one of the most elegant in mathematics.
We’ve restricted attention to \mathbb{R}^2 to keep the exposition concrete, but the theory generalizes beautifully. Vector spaces can be infinite-dimensional (spaces of functions, sequences, polynomials). Dual spaces, which we glimpsed through linear functionals, lead to the theory of differential forms and the exterior calculus that is used in modern geometry and physics.
If this chapter sparked your curiosity, consider it an invitation. Linear algebra is one of the most useful areas of mathematics—it appears in computer graphics, machine learning, optimization, quantum computing, and differential geometry. The conceptual clarity it provides is worth the initial investment.
8.7.2 Looking Ahead
In the next chapter, we define the derivative using the limit of a linear approximation. The question “what is the tangent line to f at a?” becomes: “what is the unique linear map T such that \lim_{h \to 0} \frac{|f(a+h) - f(a) - T(h)|}{|h|} = 0?”
This formulation—defining the derivative as the linear map with vanishing approximation error—makes precise what we mean by “best linear fit.” It also reveals why differentiation obeys the rules it does: the chain rule becomes composition of linear maps, the product rule reflects how approximations interact, and the geometric meaning of f'(a) as the slope of the tangent line emerges naturally.