13 Numerical Integration
13.1 The Approximation Problem
The Fundamental Theorem (Theorem 9.4) reduces integration to antidifferentiation: given F with F' = f, we compute \int_a^b f(x)\,dx = F(b) - F(a).
This is computationally trivial—two function evaluations suffice. But the theorem presumes we possess F in closed form. For many functions, this assumption fails.
Consider \int_0^1 e^{-x^2}\,dx. The integrand e^{-x^2} is continuous, hence integrable. The Fundamental Theorem guarantees the integral exists as a definite real number. Yet no combination of polynomials, exponentials, logarithms, and trigonometric functions produces an antiderivative. We proved in Elementary Integrals that e^{-x^2} admits a power series antiderivative, but for practical computation—when a numerical value is required—this does not suffice.
We face a gap: theoretical existence versus computational access. The Riemann integral exists as the limit of approximating sums (Section 8.7), but we defined it as an infinite process—taking finer and finer partitions. To compute numerically, we must halt at finite precision.
This chapter develops systematic methods for approximating \int_a^b f(x)\,dx using only function evaluations at finitely many points. We establish error bounds showing how accuracy improves as we sample more points. The methods derive from the definition of the Riemann integral itself: approximate f by simpler functions (constants, lines, parabolas), integrate the approximation exactly, and control the error.
Historical note. Before calculus, quadrature (finding areas) relied on geometric dissections and limiting arguments—Archimedes’ method of exhaustion being the paradigm. Newton and Leibniz revolutionized this by connecting integration to differentiation, reducing quadrature to finding antiderivatives. But when antiderivatives proved elusive, 18th-century mathematicians (Cotes, Simpson, Euler) developed systematic approximation schemes. These remain foundational in numerical analysis.
Modern relevance. While antiderivatives are theoretically elegant, computational practice often bypasses them. Numerical integration underpins:
Finite element methods (structural engineering, fluid dynamics)
Monte Carlo simulation (statistical mechanics, finance)
Machine learning (training neural networks involves high-dimensional integrals)
Computer graphics (rendering realistic lighting requires integrating over surfaces)
We will mention these connections where natural, but our focus remains mathematical: understanding approximation schemes rigorously.
13.2 Rectangular Approximations
Return to the definition of the Riemann integral. Given partition P = \{x_0, x_1, \ldots, x_n\} of [a,b], we formed sums S(f, P, \{t_i\}) = \sum_{i=1}^{n} f(t_i)(x_i - x_{i-1}), where t_i \in [x_{i-1}, x_i] is arbitrary (Section 8.8). As \|P\| \to 0, these converge to \int_a^b f regardless of sample point choice.
For numerical work, we fix a partition and sample points. The three natural choices:
Left endpoint: t_i = x_{i-1} L_n = \sum_{i=1}^{n} f(x_{i-1})(x_i - x_{i-1}).
Right endpoint: t_i = x_i R_n = \sum_{i=1}^{n} f(x_i)(x_i - x_{i-1}).
Midpoint: t_i = (x_{i-1} + x_i)/2 M_n = \sum_{i=1}^{n} f\left(\frac{x_{i-1} + x_i}{2}\right)(x_i - x_{i-1}).
For uniform partitions with \Delta x = (b-a)/n and x_i = a + i\Delta x, these simplify: L_n = \Delta x \sum_{i=0}^{n-1} f(x_i), \quad R_n = \Delta x \sum_{i=1}^{n} f(x_i), \quad M_n = \Delta x \sum_{i=1}^{n} f(x_{i-1/2}), where x_{i-1/2} = a + (i - 1/2)\Delta x.
Geometric interpretation. Each sum approximates the area under f by rectangles:
L_n uses left heights—underestimates if f increases, overestimates if f decreases
R_n uses right heights—opposite behavior
M_n uses midpoint heights—often more accurate than either endpoint
Example 13.1 (Rectangular Approximations) Approximate \int_0^1 x^2\,dx using n=4 subintervals.
We have \Delta x = 1/4 and x_i = i/4. Compute: \begin{align*} L_4 &= \frac{1}{4}\left[f(0) + f(1/4) + f(1/2) + f(3/4)\right] \\ &= \frac{1}{4}\left[0 + \frac{1}{16} + \frac{1}{4} + \frac{9}{16}\right] = \frac{1}{4} \cdot \frac{14}{16} = \frac{7}{32} = 0.21875. \end{align*}
\begin{align*} R_4 &= \frac{1}{4}\left[f(1/4) + f(1/2) + f(3/4) + f(1)\right] \\ &= \frac{1}{4}\left[\frac{1}{16} + \frac{1}{4} + \frac{9}{16} + 1\right] = \frac{1}{4} \cdot \frac{30}{16} = \frac{15}{32} = 0.46875. \end{align*}
\begin{align*} M_4 &= \frac{1}{4}\left[f(1/8) + f(3/8) + f(5/8) + f(7/8)\right] \\ &= \frac{1}{4}\left[\frac{1}{64} + \frac{9}{64} + \frac{25}{64} + \frac{49}{64}\right] = \frac{1}{4} \cdot \frac{84}{64} = \frac{21}{64} = 0.328125. \end{align*}
The exact value (from the Second Fundamental Theorem) is \int_0^1 x^2\,dx = [x^3/3]_0^1 = 1/3 \approx 0.333\ldots. The midpoint rule gives the closest approximation.
13.3 The Trapezoidal Rule
Rectangular approximations treat f as piecewise constant on each subinterval. We can do better by approximating f with piecewise linear functions.
On [x_{i-1}, x_i], the linear interpolant through (x_{i-1}, f(x_{i-1})) and (x_i, f(x_i)) is \ell_i(x) = f(x_{i-1}) + \frac{f(x_i) - f(x_{i-1})}{x_i - x_{i-1}}(x - x_{i-1}).
Integrate: \int_{x_{i-1}}^{x_i} \ell_i(x)\,dx = \frac{f(x_{i-1}) + f(x_i)}{2}(x_i - x_{i-1}).
This is the area of a trapezoid with parallel sides f(x_{i-1}) and f(x_i) and width x_i - x_{i-1}.
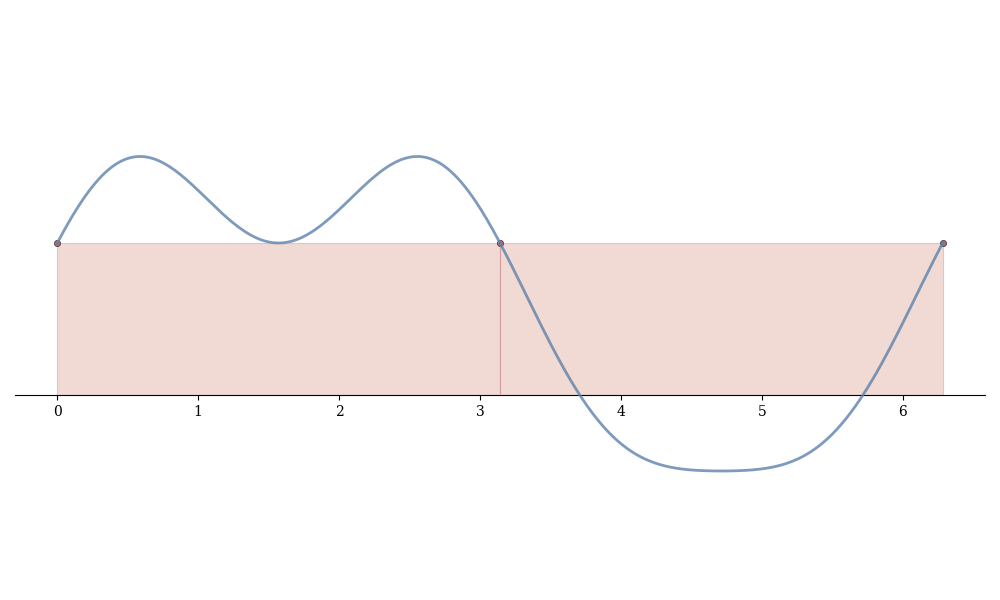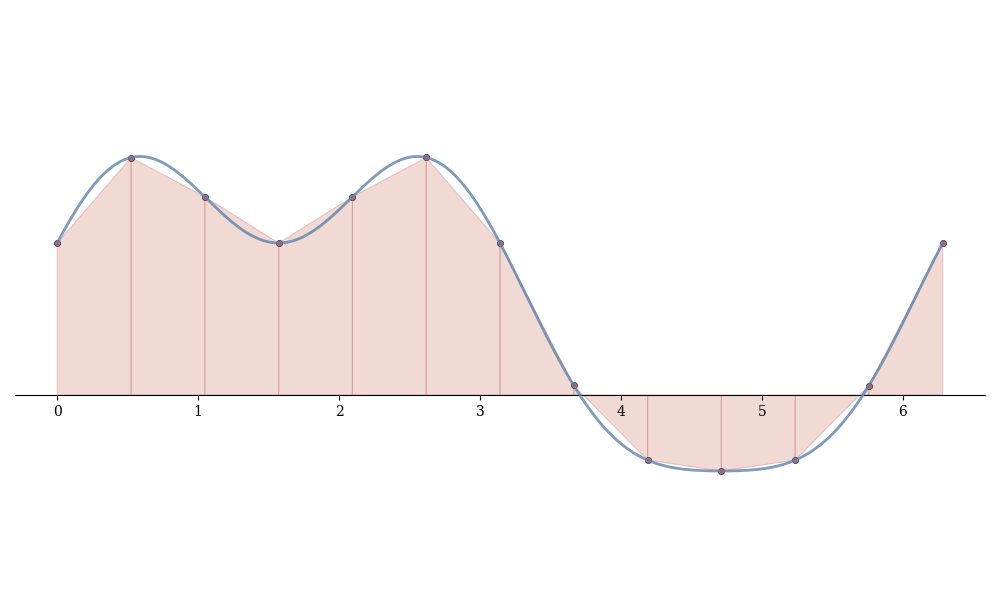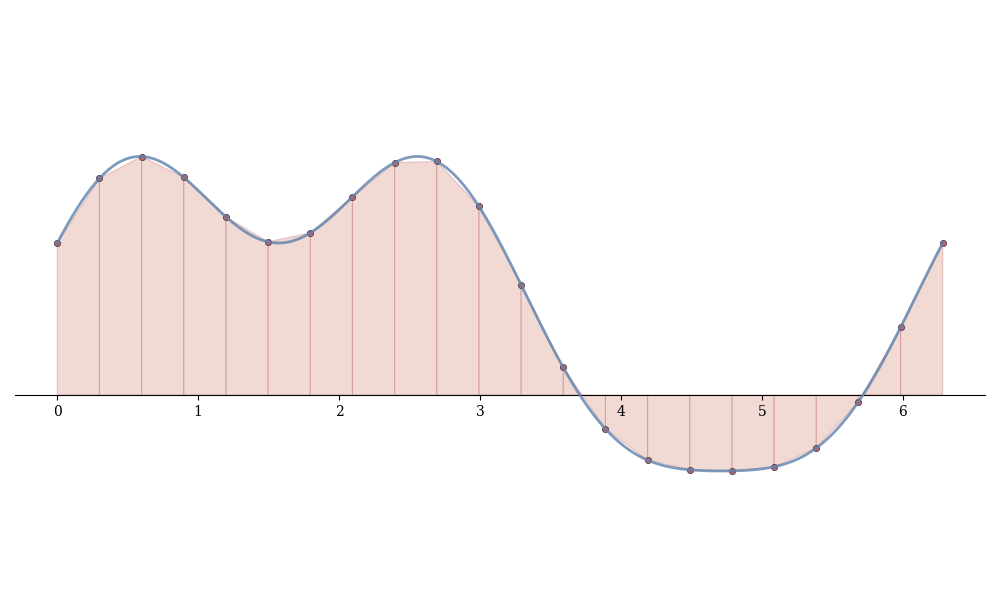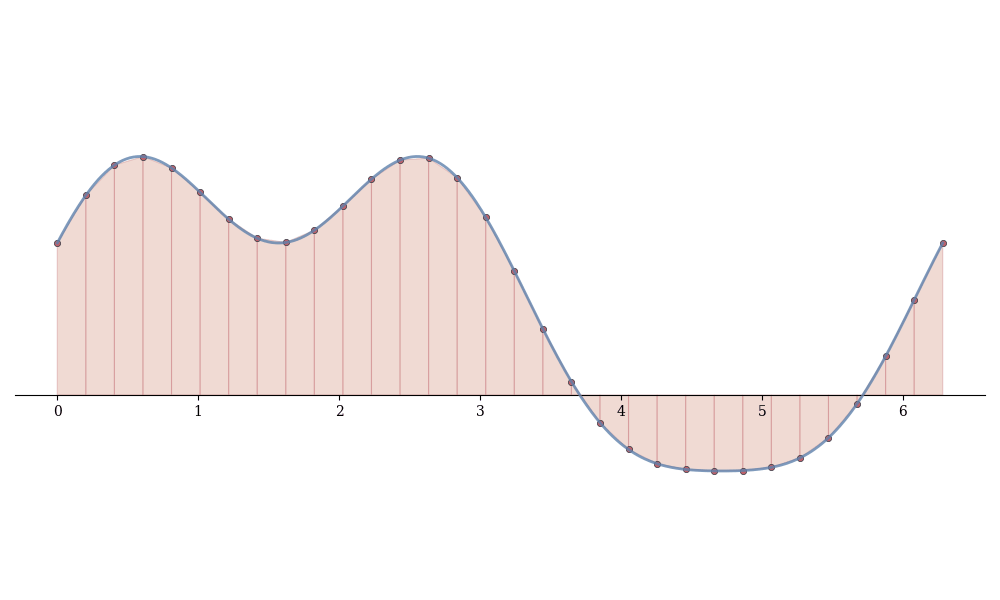
Summing over all subintervals:
Definition 13.1 (Trapezoidal Rule) T_n = \sum_{i=1}^{n} \frac{f(x_{i-1}) + f(x_i)}{2}(x_i - x_{i-1}).
For uniform partitions with \Delta x = (b-a)/n: T_n = \frac{\Delta x}{2}\left[f(x_0) + 2f(x_1) + 2f(x_2) + \cdots + 2f(x_{n-1}) + f(x_n)\right].
The formula has a pleasing structure: endpoints are weighted 1/2, interior points are weighted 1.
Relation to rectangular rules. Observe: T_n = \frac{L_n + R_n}{2}.
The trapezoidal rule is the average of left and right endpoint approximations. This symmetry often improves accuracy.
Example 13.2 (Trapezoidal Rule Application) For \int_0^1 x^2\,dx with n=4: \begin{align*} T_4 &= \frac{1/4}{2}\left[f(0) + 2f(1/4) + 2f(1/2) + 2f(3/4) + f(1)\right] \\ &= \frac{1}{8}\left[0 + 2 \cdot \frac{1}{16} + 2 \cdot \frac{1}{4} + 2 \cdot \frac{9}{16} + 1\right] \\ &= \frac{1}{8}\left[\frac{2}{16} + \frac{8}{16} + \frac{18}{16} + \frac{16}{16}\right] = \frac{1}{8} \cdot \frac{44}{16} = \frac{11}{32} = 0.34375. \end{align*}
This is closer to 1/3 than either L_4 or R_4.
Computational cost. The trapezoidal rule requires n+1 function evaluations (the partition points). Rectangular rules also require n or n+1 evaluations. The improvement comes not from reduced cost but from exploiting function smoothness.
13.4 Simpson’s Rule
The trapezoidal rule approximates f by piecewise linear functions. If f is smooth, we can use piecewise quadratics for better accuracy.
Divide [a,b] into an even number of subintervals: n = 2m. On each pair [x_{2i-2}, x_{2i-1}, x_{2i}], fit a parabola through the three points (x_{2i-2}, f(x_{2i-2})), (x_{2i-1}, f(x_{2i-1})), (x_{2i}, f(x_{2i})) and integrate.
For uniform spacing \Delta x = (b-a)/n, the integral of the parabola over [x_{2i-2}, x_{2i}] equals \frac{\Delta x}{3}\left[f(x_{2i-2}) + 4f(x_{2i-1}) + f(x_{2i})\right].
We defer the derivation of this formula (it follows from Lagrange interpolation), stating the result:
Definition 13.2 (Simpson’s Rule) For n = 2m even and uniform partition: S_n = \frac{\Delta x}{3}\left[f(x_0) + 4f(x_1) + 2f(x_2) + 4f(x_3) + 2f(x_4) + \cdots + 4f(x_{n-1}) + f(x_n)\right].
Pattern: endpoints weighted 1, odd indices weighted 4, even interior indices weighted 2.

Example 13.3 (Simpson’s Rule Exactness) For \int_0^1 x^2\,dx with n=4 (so m=2): \begin{align*} S_4 &= \frac{1/4}{3}\left[f(0) + 4f(1/4) + 2f(1/2) + 4f(3/4) + f(1)\right] \\ &= \frac{1}{12}\left[0 + 4 \cdot \frac{1}{16} + 2 \cdot \frac{1}{4} + 4 \cdot \frac{9}{16} + 1\right] \\ &= \frac{1}{12}\left[\frac{4}{16} + \frac{8}{16} + \frac{36}{16} + \frac{16}{16}\right] = \frac{1}{12} \cdot \frac{64}{16} = \frac{1}{3}. \end{align*}
Simpson’s rule gives the exact answer. This is not coincidence—Simpson’s rule is exact for polynomials up to degree 3, and x^2 is such a polynomial. We establish this shortly.
Historical note. Thomas Simpson (1710–1761) popularized this formula in his textbook Mathematical Dissertations (1743), though Newton knew it earlier. It became the standard for practical quadrature in pre-computer era navigation and astronomy.
13.5 Error Analysis
We have described approximation schemes, but without error bounds, they are useless. How rapidly do T_n and S_n converge to \int_a^b f? How many subintervals are required for prescribed accuracy?
Error analysis is the soul of numerical methods. Without it, we cannot distinguish good approximations from bad, nor predict when to trust computed values.
13.5.1 Trapezoidal Rule Error
Theorem 13.1 (Trapezoidal Rule Error Bound) Let f \in C^2([a,b]) (twice continuously differentiable). Then \left|\int_a^b f(x)\,dx - T_n\right| \leq \frac{(b-a)^3}{12n^2} \max_{x \in [a,b]} |f''(x)|.
The error decreases as O(1/n^2)—doubling n reduces error by a factor of 4. The bound depends on the second derivative: the more f curves, the larger the error.
We prove the bound for a single subinterval [x_{i-1}, x_i] and sum.
Let h = x_i - x_{i-1} and assume for simplicity that [x_{i-1}, x_i] = [0, h] (by translation). The trapezoidal approximation is T_i = \frac{h}{2}[f(0) + f(h)].
The exact integral is I_i = \int_0^h f(x)\,dx.
Define the error E_i = I_i - T_i. We seek a bound on |E_i|.
We use integration by parts to express the error in terms of f''.
Write the exact integral using the “kernel trick.” Choose v(x) = x - h/2 (which satisfies v(0) = -h/2, v(h) = h/2) and integrate by parts: \int_0^h f(x)\,dx = \int_0^h f(x) \cdot 1\,dx = \left[f(x)(x - h/2)\right]_0^h - \int_0^h f'(x)(x - h/2)\,dx.
The boundary term gives f(h) \cdot h/2 + f(0) \cdot h/2 = \frac{h}{2}[f(0) + f(h)] = T_i. Therefore: E_i = I_i - T_i = -\int_0^h f'(x)(x - h/2)\,dx.
Integrate by parts again, choosing v(x) = \frac{1}{2}(x - h/2)^2 - \frac{h^2}{8} (which vanishes at x = 0 and x = h, killing the boundary terms): E_i = -\left[f'(x) v(x)\right]_0^h + \int_0^h f''(x)\left[\frac{(x - h/2)^2}{2} - \frac{h^2}{8}\right]dx = \int_0^h f''(x)\left[\frac{(x - h/2)^2}{2} - \frac{h^2}{8}\right]dx.
Since \frac{(x-h/2)^2}{2} - \frac{h^2}{8} \leq 0 on [0,h] (verify: the maximum of (x-h/2)^2/2 on [0,h] is h^2/8, attained at the endpoints), the kernel does not change sign. By the mean value theorem for integrals, there exists \xi_i \in [0,h] such that: E_i = f''(\xi_i) \int_0^h \left[\frac{(x - h/2)^2}{2} - \frac{h^2}{8}\right]dx = f''(\xi_i) \left[\frac{h^3}{24} - \frac{h^3}{8}\right] = -\frac{h^3}{12}f''(\xi_i).
Therefore: |E_i| \leq \frac{M_2 h^3}{12}.
For the full interval [a,b] with n subintervals of width h = (b-a)/n: \left|\sum_{i=1}^{n} E_i\right| \leq n \cdot \frac{M_2 h^3}{12} = \frac{M_2}{12} \cdot n \cdot \frac{(b-a)^3}{n^3} = \frac{M_2 (b-a)^3}{12n^2}.
Setting M_2 = \max_{[a,b]} |f''| yields the result. \square
Example 13.4 (Error Bound Application) Bound the error for \int_0^1 x^2\,dx using T_4.
We have f(x) = x^2, so f''(x) = 2, giving \max |f''| = 2. The bound is: \left|\int_0^1 x^2\,dx - T_4\right| \leq \frac{(1-0)^3}{12 \cdot 4^2} \cdot 2 = \frac{1}{96} \approx 0.0104.
The actual error is |1/3 - 11/32| = |32/96 - 33/96| = 1/96—the bound is sharp.
13.5.2 Simpson’s Rule Error
Theorem 13.2 (Simpson’s Rule Error Bound) Let f \in C^4([a,b]). Then \left|\int_a^b f(x)\,dx - S_n\right| \leq \frac{(b-a)^5}{180n^4} \max_{x \in [a,b]} |f^{(4)}(x)|.
The error is O(1/n^4)—quadrupling n reduces error by a factor of 256. Simpson’s rule converges much faster than the trapezoidal rule when f is smooth.
Moreover, the error depends on the fourth derivative. If f is a polynomial of degree \leq 3, then f^{(4)} = 0, so the error is zero—Simpson’s rule is exact for cubics.
The proof follows the same pattern as for the trapezoidal rule but requires Taylor expansion to fourth order. We omit the details, which involve tedious but straightforward calculus.
The key insight: fitting parabolas matches up to the second derivative at each point. The error comes from the third and fourth derivatives. Remarkably, by symmetry, the third-derivative terms cancel, leaving only fourth-order error. This explains the O(h^4) behavior. \square
Example 13.5 (Simpson’s Rule Error Bound) For \int_0^1 e^{-x^2}\,dx, bound the error using S_{10}.
We have f(x) = e^{-x^2}. Computing derivatives: f'(x) = -2xe^{-x^2}, \quad f''(x) = (4x^2 - 2)e^{-x^2}, \quad \ldots
The fourth derivative is a degree-4 polynomial times e^{-x^2}. On [0,1], we have |e^{-x^2}| \leq 1. By explicit computation (or symbolic software), \max_{[0,1]} |f^{(4)}(x)| \leq 12 (this is a rough bound).
Thus: \left|\int_0^1 e^{-x^2}\,dx - S_{10}\right| \leq \frac{1^5}{180 \cdot 10^4} \cdot 12 = \frac{12}{1800000} \approx 6.7 \times 10^{-6}.
With 10 subintervals (hence 11 function evaluations), Simpson’s rule achieves six-digit accuracy.
13.6 Adaptive Quadrature
The error bounds in Theorem 13.1 and Theorem 13.2 are global—they apply uniformly over [a,b]. But functions often vary in smoothness. Near a singularity or rapid oscillation, more sampling is needed; elsewhere, fewer points suffice.
Adaptive quadrature allocates computational effort where it’s needed, refining the partition in regions of high error.
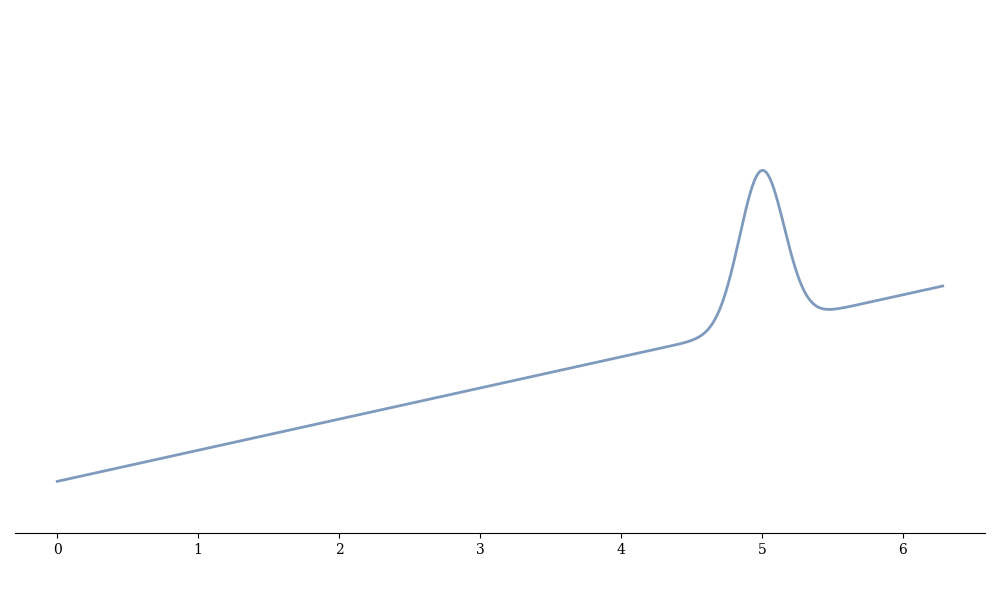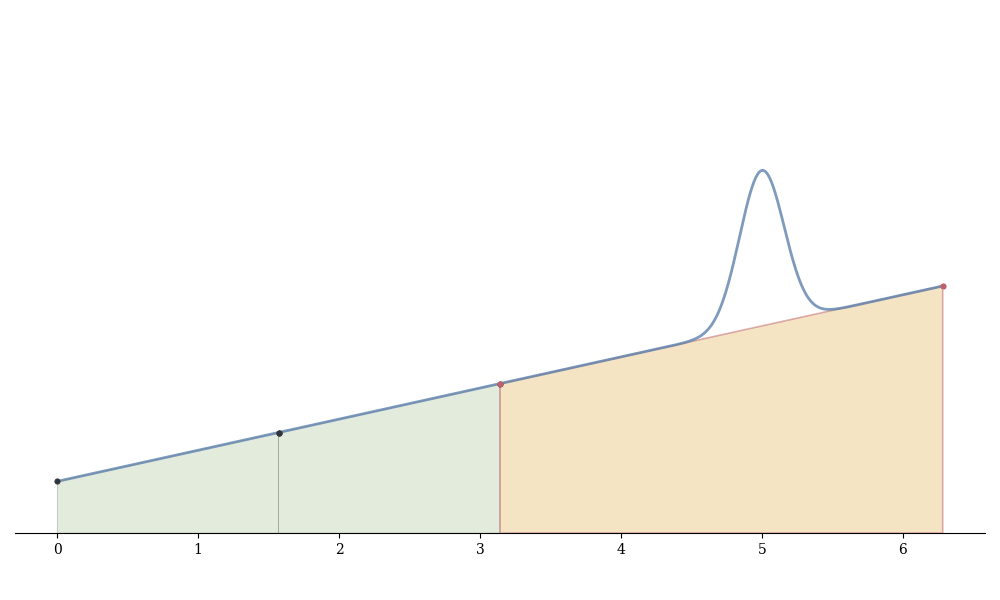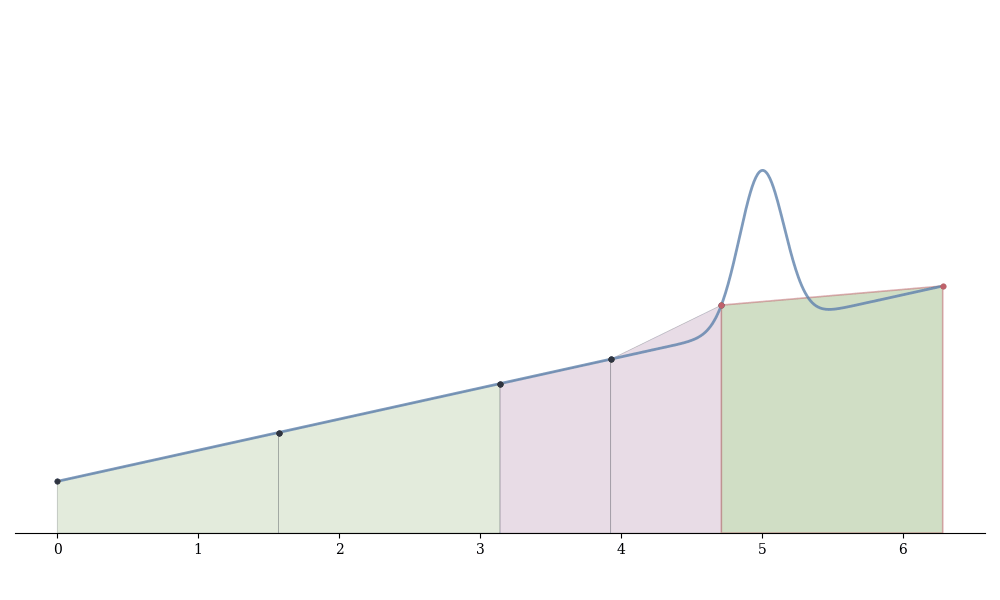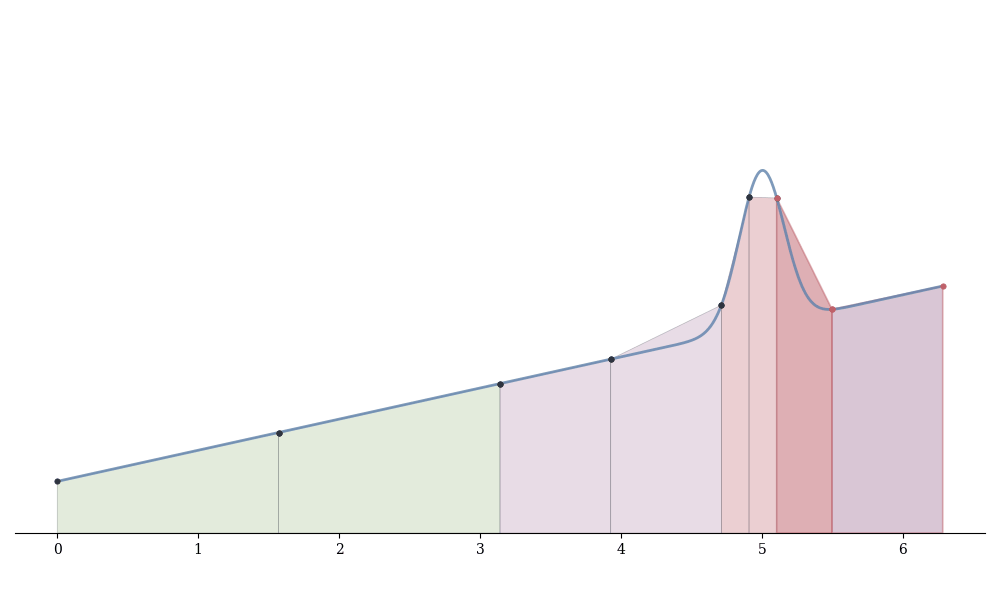
The basic idea:
Estimate the integral on [a,b] using n points: I_n \approx \int_a^b f
Estimate using 2n points: I_{2n} \approx \int_a^b f
If |I_{2n} - I_n| < \varepsilon (user tolerance), accept I_{2n}
Otherwise, split [a,b] at midpoint c = (a+b)/2 and recursively apply to [a,c] and [c,b]
The difference |I_{2n} - I_n| estimates the error. When error is small, we stop refining. When large, we subdivide and repeat.
Error estimation. For Simpson’s rule, if S_n and S_{2n} denote approximations with n and 2n subintervals: \int_a^b f - S_n \approx C/n^4, \quad \int_a^b f - S_{2n} \approx C/(2n)^4 = C/(16n^4).
Subtracting: S_{2n} - S_n \approx \left(1 - \frac{1}{16}\right)\frac{C}{n^4} = \frac{15C}{16n^4}.
Thus: \int_a^b f - S_{2n} \approx \frac{1}{15}(S_{2n} - S_n).
The difference S_{2n} - S_n estimates the error in S_{2n} up to a constant factor. Requiring |S_{2n} - S_n|/15 < \varepsilon ensures |\int_a^b f - S_{2n}| \lesssim \varepsilon.
Advantages. Adaptive methods automatically handle irregular integrands without user intervention. They are the basis of modern numerical integration libraries (e.g., scipy.integrate.quad in Python, quadgk in Julia).
Remark on high dimensions. In one dimension, adaptive quadrature is efficient. In higher dimensions, the curse of dimensionality intervenes—grids grow exponentially with dimension. For d-dimensional integrals with n points per axis, we need n^d total evaluations. For d=10 and n=100, this is 10^{20} evaluations, computationally infeasible. Alternative methods (Monte Carlo, quasi-Monte Carlo) become necessary. We briefly discuss this in Section 13.8.
13.7 Newton-Cotes Formulas: General Theory
The trapezoidal and Simpson’s rules are instances of a broader class: Newton-Cotes formulas.
Definition 13.3 (Newton-Cotes Formula) Given n+1 equally spaced points x_0, x_1, \ldots, x_n in [a,b], the closed Newton-Cotes formula approximates \int_a^b f(x)\,dx \approx (b-a) \sum_{i=0}^{n} w_i f(x_i), where the weights w_i are determined by requiring exactness for polynomials of degree \leq n.
Exactness condition. The formula must integrate 1, x, x^2, \ldots, x^n exactly. This yields n+1 linear equations for the n+1 weights w_i.
Examples:
n=1 (Trapezoidal rule): Two points, linear interpolation, exact for degree \leq 1
Weights: w_0 = w_1 = 1/2
n=2 (Simpson’s rule): Three points, quadratic interpolation, exact for degree \leq 3 (!)
Weights: w_0 = 1/6, w_1 = 4/6, w_2 = 1/6
n=3 (Simpson’s 3/8 rule): Four points, cubic interpolation, exact for degree \leq 3
Weights: w_0 = 1/8, w_1 = 3/8, w_2 = 3/8, w_3 = 1/8
The remarkable fact about Simpson’s rule (n=2) is that it achieves degree 3 exactness despite using only three points—one degree higher than expected. This is due to symmetry: odd-degree terms cancel.
Higher-order formulas exist (Boole’s rule, etc.), but they become numerically unstable—high-degree polynomial interpolation through equally spaced points suffers from Runge’s phenomenon (wild oscillations near endpoints). For practical computation, low-order formulas with adaptive refinement are preferred.
Newton-Cotes formulas use equally spaced points. What if we allow points to be placed optimally?
Gaussian quadrature chooses both the points x_i and weights w_i to maximize the degree of exactness. With n points, Gaussian quadrature achieves exactness for polynomials of degree \leq 2n-1—double what Newton-Cotes achieves.
Theorem 13.3 (Gaussian Quadrature) On [-1,1] with n points, the formula \int_{-1}^{1} f(x)\,dx \approx \sum_{i=1}^{n} w_i f(x_i) is exact for all polynomials of degree \leq 2n-1 if and only if the x_i are the zeros of the n-th Legendre polynomial P_n(x).
Legendre polynomials are orthogonal polynomials on [-1,1] with respect to the inner product \langle f, g \rangle = \int_{-1}^{1} f(x)g(x)\,dx. Their zeros are the optimal quadrature points.
Example: n=2 (two-point Gaussian rule).
The second Legendre polynomial is P_2(x) = \frac{1}{2}(3x^2 - 1), with zeros at x_1 = -1/\sqrt{3} and x_2 = 1/\sqrt{3}. The weights are w_1 = w_2 = 1.
The formula: \int_{-1}^{1} f(x)\,dx \approx f(-1/\sqrt{3}) + f(1/\sqrt{3}) is exact for all polynomials of degree \leq 3—matching Simpson’s rule with only two evaluations instead of three.
For general intervals [a,b], use the change of variables t = \frac{2x - (a+b)}{b-a} to map [a,b] to [-1,1].
Advantages. Gaussian quadrature achieves higher accuracy per function evaluation than Newton-Cotes formulas. It is the method of choice when function evaluations are expensive (e.g., solving differential equations at each point).
Disadvantages. The points are non-uniform and irrational, complicating adaptive refinement. For functions with singularities or discontinuities, adaptive Newton-Cotes may perform better.
13.8 Connections to Modern Computation
The methods developed here—rectangular, trapezoidal, Simpson’s, Gaussian—remain foundational in computational science. We briefly survey connections without digressing from our mathematical focus.
13.8.1 High-Dimensional Integration and Monte Carlo
For d-dimensional integrals \int_{\Omega} f(\mathbf{x})\,d\mathbf{x}, \quad \mathbf{x} \in \mathbb{R}^d, deterministic quadrature becomes impractical for d \geq 4 due to exponential growth in grid points.
Monte Carlo integration replaces structured grids with random sampling: \int_{\Omega} f(\mathbf{x})\,d\mathbf{x} \approx \frac{|\Omega|}{N} \sum_{i=1}^{N} f(\mathbf{x}_i), where \mathbf{x}_i are uniformly random points in \Omega. By the law of large numbers, this converges as O(1/\sqrt{N})—independent of dimension.
This underpins:
Statistical mechanics: Computing thermodynamic averages over high-dimensional phase spaces
Bayesian inference: Evaluating posterior probabilities in machine learning
Computer graphics: Rendering realistic lighting via path tracing
Monte Carlo trades deterministic guarantees for dimensional independence. For smooth low-dimensional integrals, Gaussian quadrature is superior. For rough high-dimensional integrals, Monte Carlo is the only feasible approach.
13.8.2 Finite Element Methods
Solving partial differential equations (PDEs) numerically—fluid flow, structural mechanics, electromagnetics—requires integrating over complex domains. The finite element method discretizes the domain into small elements (triangles, tetrahedra) and approximates the solution by piecewise polynomials.
Evaluating integrals over each element uses Gaussian quadrature. The accuracy of the PDE solution depends critically on accurate numerical integration. Simpson’s rule and higher-order Newton-Cotes formulas extend naturally to multi-dimensional elements.
This connects our one-dimensional theory to problems of immense practical importance: designing aircraft wings, simulating climate, modeling protein folding.
13.8.3 Machine Learning and Numerical Integration
Training neural networks involves optimizing \mathcal{L}(\theta) = \int p(x) \ell(f_\theta(x), y(x))\,dx, where p(x) is a data distribution, f_\theta is the network, and \ell is a loss function. In practice, integrals are approximated by sums over mini-batches—a form of Monte Carlo sampling.
More subtly, automatic differentiation (backpropagation) relies on the chain rule, which we developed rigorously in Calculus 1. The gradient \frac{\partial \mathcal{L}}{\partial \theta} propagates through compositions of functions, applying the chain rule at each layer. Understanding derivatives as linear maps (§ Vectors and Linear Maps) clarifies why automatic differentiation works: each layer applies a linear approximation, and the chain rule composes these approximations.
13.9 Remark on Limitations
We have developed methods for univariate integrals of smooth functions. Several important extensions lie beyond our scope:
Singular integrands. Functions like \int_0^1 x^{-1/2}\,dx are integrable but unbounded. Standard quadrature fails near singularities. Specialized techniques (change of variables, subtraction of singularity) are required.
Oscillatory integrands. Functions like \int_0^{\infty} \sin(x^2)\,dx oscillate rapidly. Standard methods converge slowly. Stationary phase and Filon-type methods exploit cancellation between oscillations.
Infinite intervals. For \int_0^{\infty} e^{-x^2}\,dx, we must truncate or transform the interval. Change of variables x = \tan(t) maps [0,\infty) to [0,\pi/2] at the cost of a singular integrand.
Non-smooth functions. If f has jump discontinuities, error bounds depending on higher derivatives fail. Adaptive quadrature can handle this by detecting the jumps, but care is needed.
These are active areas in numerical analysis. Our goal has been to establish the foundational methods and error analysis framework. Extensions follow the same principles: approximate, bound error, refine adaptively.
13.10 Summary
We have developed the theory of numerical integration from first principles:
Rectangular rules arise directly from the Riemann integral definition, providing O(1/n) convergence
Trapezoidal rule approximates via piecewise linear interpolation, achieving O(1/n^2) convergence
Simpson’s rule uses piecewise quadratic interpolation, achieving O(1/n^4) convergence for smooth functions
Error bounds quantify convergence rates rigorously, connecting to higher derivatives
These methods form the computational backbone of modern scientific computing. While we focused on one dimension, the principles—approximation by simpler functions, error control via derivatives, adaptive refinement—extend to higher dimensions and underpin finite element methods, Monte Carlo simulation, and numerical solutions of differential equations.
The key insight remains: the Riemann integral is an infinite process, but finite approximations suffice when controlled rigorously. Understanding the error tells us when to stop refining—and that understanding flows directly from the analytical tools of calculus.
Rectangular and trapezoidal approximations for exponential functions.
Let f(x) = e^x on [0,1] with uniform partition of width \Delta x = 1/n. Compute the right and left endpoint approximations R_n and L_n explicitly as geometric series, then prove that R_n - L_n = \frac{e-1}{n}.
Using the fact that T_n = \frac{L_n + R_n}{2} from Definition 13.1, show that T_n = \frac{e-1}{2n}\left(\frac{e^{1/n}+1}{e^{1/n}-1}\right). Expand e^{1/n} as a Taylor series to second order and compute \lim_{n \to \infty} n(e - 1 - T_n). Explain why this limit tells us the leading-order error term.
Simpson’s rule exactness and symmetry properties.
Verify directly that Simpson’s rule S_n is exact for f(x) = x^3 on [-1,1] by computing S_2 (with n = 2, so one parabola) and comparing to \int_{-1}^{1} x^3\,dx. Then explain why exactness for \{1, x, x^2, x^3\} implies exactness for all cubic polynomials by linearity of the integral.
For \int_0^{\pi} \sin x\,dx = 2, compute S_4 explicitly using \Delta x = \pi/4. Then apply Theorem 13.2 with f^{(4)}(x) = \sin x to bound the error. Compare your error bound to the actual error |2 - S_4|.
Prove that if f is even on [-c,c] (so f(-x) = f(x)), then Simpson’s rule S_n can be computed using only function values at non-negative points. Specifically, show that f(x_i) = f(x_{n-i}) and that the symmetry of the Simpson weights allows pairing of terms.
Gaussian quadrature versus Newton-Cotes formulas.
The two-point Gaussian quadrature rule on [-1,1] is \int_{-1}^{1} f(x)\,dx \approx f(-1/\sqrt{3}) + f(1/\sqrt{3}). Verify that this formula is exact for f(x) = x^3 by direct computation. Then verify exactness for f(x) = x^2 as well.
For the integral \int_0^1 x^4\,dx = 1/5, compute both Simpson’s rule S_2 (using n=2 subintervals) and the two-point Gaussian rule (after changing variables t = 2x - 1 to map [0,1] to [-1,1]). Which approximation is more accurate? Explain why Gaussian quadrature can be more accurate despite using fewer function evaluations.
Compare the polynomial exactness of the two-point Gaussian rule versus Simpson’s rule (three-point). Both achieve exactness for polynomials of degree \leq 3, but how many function evaluations does each require? This illustrates the power of Theorem 13.3: optimal placement of points doubles the degree of exactness compared to equally-spaced points.
Error estimation and adaptive refinement strategies.
Suppose a quadrature rule I_n approximates \int_a^b f with error satisfying \left|\int_a^b f - I_n\right| \leq Cn^{-\alpha} for constants C, \alpha > 0. Derive the Richardson extrapolation formula \int_a^b f - I_{2n} \approx \frac{I_{2n} - I_n}{2^\alpha - 1} by assuming the error has the form \int_a^b f = I_n + Cn^{-\alpha} + O(n^{-2\alpha}) and solving for the constant C by comparing I_n and I_{2n}.
For Simpson’s rule (\alpha = 4), suppose S_4 = 1.3333 and S_8 = 1.3334. Use the formula from part (a) to estimate the error in S_8. Explain how this adaptive error estimate allows us to determine when to stop refining without knowing the exact integral value.
Given f \in C^4([a,b]) with |f^{(4)}(x)| \leq M = 24 on [0,1], use Theorem 13.2 to determine the minimum even integer n such that Simpson’s rule achieves accuracy \varepsilon = 10^{-6}. Show your work in solving the inequality.
Analysis of trapezoidal rule for f(x) = e^x.
Computing rectangular approximations. With uniform partition \Delta x = 1/n and x_i = i/n for i = 0, \ldots, n:
The left endpoint rule gives L_n = \frac{1}{n}\sum_{i=0}^{n-1} e^{i/n} = \frac{1}{n}\sum_{i=0}^{n-1} (e^{1/n})^i = \frac{1}{n} \cdot \frac{1 - e^{(n)(1/n)}}{1 - e^{1/n}} = \frac{1}{n} \cdot \frac{1 - e}{1 - e^{1/n}}.
Using the geometric series formula with ratio r = e^{1/n} and n terms (from i=0 to i=n-1).
Similarly, the right endpoint rule gives R_n = \frac{1}{n}\sum_{i=1}^{n} e^{i/n} = \frac{1}{n}\sum_{i=1}^{n} (e^{1/n})^i = \frac{1}{n} \cdot \frac{e^{1/n}(1 - e)}{1 - e^{1/n}}.
The difference is \begin{align*} R_n - L_n &= \frac{1}{n} \cdot \frac{e^{1/n}(1-e) - (1-e)}{1 - e^{1/n}} \\ &= \frac{1}{n} \cdot \frac{(e^{1/n} - 1)(1-e)}{1 - e^{1/n}} \\ &= \frac{1}{n}(1 - e) = \frac{e-1}{n}. \end{align*}
This shows the difference between right and left approximations decays linearly in n, as expected from the general theory. \square
Asymptotic expansion of the trapezoidal rule. Since T_n = \frac{L_n + R_n}{2} by Definition 13.1, we have T_n = \frac{1}{2n} \cdot \frac{(1 + e^{1/n})(1-e)}{1 - e^{1/n}} = \frac{e-1}{2n} \cdot \frac{1 + e^{1/n}}{e^{1/n} - 1}.
Now expand e^{1/n} using Taylor series: e^{1/n} = 1 + \frac{1}{n} + \frac{1}{2n^2} + \frac{1}{6n^3} + O(1/n^4).
The numerator becomes 1 + e^{1/n} = 2 + \frac{1}{n} + \frac{1}{2n^2} + O(1/n^3).
The denominator becomes e^{1/n} - 1 = \frac{1}{n} + \frac{1}{2n^2} + \frac{1}{6n^3} + O(1/n^4).
Therefore, \frac{1 + e^{1/n}}{e^{1/n} - 1} = \frac{2 + \frac{1}{n} + O(1/n^2)}{\frac{1}{n}(1 + \frac{1}{2n} + O(1/n^2))} = n \cdot \frac{2 + \frac{1}{n} + O(1/n^2)}{1 + \frac{1}{2n} + O(1/n^2)}.
Using (1 + x)^{-1} = 1 - x + O(x^2) for small x: \frac{1 + e^{1/n}}{e^{1/n} - 1} = n\left(2 + \frac{1}{n}\right)\left(1 - \frac{1}{2n} + O(1/n^2)\right) = 2n - 1 + \frac{1}{n} + O(1/n).
Thus T_n = \frac{e-1}{2n}(2n - 1 + O(1/n)) = (e-1)\left(1 - \frac{1}{2n} + O(1/n^2)\right).
Taking the limit: \lim_{n \to \infty} n(e - 1 - T_n) = \lim_{n \to \infty} n \cdot (e-1) \cdot \frac{1}{2n} = \frac{e-1}{2}.
This shows the error in T_n is asymptotically \frac{e-1}{2n}, giving us the leading coefficient in the error expansion. This is the key quantity in Richardson extrapolation for improving approximations. \square
Simpson’s rule for polynomials and trigonometric functions.
Verifying exactness for cubics. On [-1,1] with n=2, we have \Delta x = 1 and points x_0 = -1, x_1 = 0, x_2 = 1.
For f(x) = x^3: S_2 = \frac{1}{3}[f(-1) + 4f(0) + f(1)] = \frac{1}{3}[(-1) + 4(0) + 1] = \frac{1}{3}[0] = 0.
The exact integral is \int_{-1}^{1} x^3\,dx = \left[\frac{x^4}{4}\right]_{-1}^{1} = 0.
Simpson’s rule is exact! This verifies exactness for one cubic. For any cubic p(x) = a_0 + a_1 x + a_2 x^2 + a_3 x^3, by linearity (Theorem 8.4 extended to approximations), S_n(p) = a_0 S_n(1) + a_1 S_n(x) + a_2 S_n(x^2) + a_3 S_n(x^3).
If Simpson’s rule is exact for the basis \{1, x, x^2, x^3\}, then it’s exact for all linear combinations, i.e., all cubics. The exactness for basis polynomials (verified by construction of the weights via parabolic interpolation) extends to the entire polynomial space by linearity. \square
Computing Simpson’s rule for sine. With \Delta x = \pi/4 and n = 4: \begin{align*} S_4 &= \frac{\pi/4}{3}\left[\sin 0 + 4\sin(\pi/4) + 2\sin(\pi/2) + 4\sin(3\pi/4) + \sin\pi\right] \\ &= \frac{\pi}{12}\left[0 + 4 \cdot \frac{\sqrt{2}}{2} + 2 \cdot 1 + 4 \cdot \frac{\sqrt{2}}{2} + 0\right] \\ &= \frac{\pi}{12}(2\sqrt{2} + 2 + 2\sqrt{2}) \\ &= \frac{\pi}{12}(4\sqrt{2} + 2) \\ &= \frac{\pi(2\sqrt{2} + 1)}{6} \approx 2.0046. \end{align*}
The exact value is \int_0^{\pi} \sin x\,dx = [-\cos x]_0^{\pi} = -(-1) - (-1) = 2.
The actual error is |2 - S_4| \approx 0.0046.
By Theorem 13.2 with f^{(4)}(x) = \sin x satisfying |f^{(4)}(x)| \leq 1 on [0,\pi]: |2 - S_4| \leq \frac{\pi^5}{180 \cdot 4^4} \cdot 1 = \frac{\pi^5}{180 \cdot 256} = \frac{\pi^5}{46080} \approx 0.0066.
The bound 0.0066 successfully captures the actual error 0.0046, confirming the O(1/n^4) convergence rate. \square
Exploiting symmetry in Simpson’s rule. Suppose f(-x) = f(x) on [-c,c]. For uniform partition with \Delta x = 2c/n and x_i = -c + i\Delta x:
By symmetry, x_{n-i} = -c + (n-i)\Delta x = c - i\Delta x = -x_i.
Therefore, f(x_i) = f(-x_i) = f(x_{n-i}).
In Simpson’s rule (Definition 13.2), the weight pattern is w_0 = 1, w_1 = 4, w_2 = 2, w_3 = 4, \ldots, w_{n-1} = 4, w_n = 1. This pattern is symmetric: w_i = w_{n-i}.
Thus terms w_i f(x_i) and w_{n-i} f(x_{n-i}) can be combined: w_i f(x_i) + w_{n-i} f(x_{n-i}) = 2w_i f(x_i) since w_i = w_{n-i} and f(x_i) = f(x_{n-i}).
This means we only need to evaluate f at non-negative points (or equivalently, at non-positive points), effectively halving the computational cost for even functions. This is particularly useful in applications like Fourier analysis where integrands are often symmetric. \square
Gaussian quadrature and optimal point placement.
Verifying Gaussian exactness. For f(x) = x^3: f(-1/\sqrt{3}) + f(1/\sqrt{3}) = -\frac{1}{3\sqrt{3}} + \frac{1}{3\sqrt{3}} = 0.
The exact integral is \int_{-1}^{1} x^3\,dx = 0. Exactness verified.
For f(x) = x^2: f(-1/\sqrt{3}) + f(1/\sqrt{3}) = \frac{1}{3} + \frac{1}{3} = \frac{2}{3}.
The exact integral is \int_{-1}^{1} x^2\,dx = \left[\frac{x^3}{3}\right]_{-1}^{1} = \frac{2}{3}. Exactness verified.
These verifications confirm that the two-point Gaussian rule achieves degree 3 exactness (it integrates 1, x, x^2, x^3 exactly). By linearity, it integrates all polynomials of degree \leq 3 exactly. \square
Comparing Simpson and Gaussian for quartics. The exact value is \int_0^1 x^4\,dx = \left[\frac{x^5}{5}\right]_0^1 = \frac{1}{5} = 0.2.
Simpson’s rule with n=2: \Delta x = 1/2, points x_0 = 0, x_1 = 1/2, x_2 = 1: \begin{align*} S_2 &= \frac{1/2}{3}[f(0) + 4f(1/2) + f(1)] \\ &= \frac{1}{6}\left[0 + 4 \cdot \frac{1}{16} + 1\right] \\ &= \frac{1}{6}\left[\frac{1}{4} + 1\right] = \frac{5}{24} \approx 0.2083. \end{align*}
Error: |0.2 - 0.2083| = 0.0083.
Gaussian quadrature: Change variables t = 2x - 1, so x = (t+1)/2 and dx = dt/2: \int_0^1 x^4\,dx = \frac{1}{2}\int_{-1}^{1} \left(\frac{t+1}{2}\right)^4 dt = \frac{1}{32}\int_{-1}^{1} (t+1)^4\,dt.
Let g(t) = (t+1)^4. Then: g(-1/\sqrt{3}) = (1 - 1/\sqrt{3})^4, \quad g(1/\sqrt{3}) = (1 + 1/\sqrt{3})^4.
Computing numerically: 1 - 1/\sqrt{3} \approx 0.4226, so (0.4226)^4 \approx 0.0318.
Similarly, 1 + 1/\sqrt{3} \approx 1.5774, so (1.5774)^4 \approx 6.2047.Therefore, \frac{1}{32}[0.0318 + 6.2047] \approx \frac{6.2365}{32} \approx 0.1949.
Error: |0.2 - 0.1949| \approx 0.0051.
Gaussian quadrature is more accurate (error 0.0051 vs 0.0083) despite both formulas failing to integrate x^4 exactly (it’s degree 4, beyond both methods’ exactness). The optimal point placement in Gaussian quadrature minimizes error even for polynomials beyond its exactness degree. \square
Efficiency comparison. Simpson’s rule (three-point Newton-Cotes):
- Number of points: 3
- Degree of exactness: 3
- Ratio: 3 points for degree 3
Two-point Gaussian rule:
- Number of points: 2
- Degree of exactness: 3 (by Theorem 13.3)
- Ratio: 2 points for degree 3
Gaussian quadrature achieves the same polynomial exactness with fewer evaluations. This is the power of optimal point placement: by choosing points as zeros of orthogonal polynomials (Legendre polynomials on [-1,1]), we maximize the degree of polynomials integrated exactly. Newton-Cotes formulas use equally-spaced points, which is natural but not optimal. The gain becomes more dramatic for higher-order rules: n-point Gaussian integrates degree 2n-1 exactly, while n-point Newton-Cotes achieves degree n (or n+1 for even n due to symmetry). \square
Adaptive error estimation and practical convergence.
Deriving Richardson extrapolation. Assume the error has asymptotic expansion \int_a^b f = I_n + Cn^{-\alpha} + O(n^{-2\alpha}).
Then \int_a^b f = I_{2n} + C(2n)^{-\alpha} + O(n^{-2\alpha}) = I_{2n} + C \cdot 2^{-\alpha} n^{-\alpha} + O(n^{-2\alpha}).
Subtracting the second from the first: I_n - I_{2n} = Cn^{-\alpha}(1 - 2^{-\alpha}) + O(n^{-2\alpha}).
Solving for Cn^{-\alpha}: Cn^{-\alpha} = \frac{I_n - I_{2n}}{1 - 2^{-\alpha}} + O(n^{-2\alpha}) = \frac{I_{2n} - I_n}{2^\alpha - 1} + O(n^{-2\alpha}).
From the second equation, \int_a^b f - I_{2n} = C \cdot 2^{-\alpha} n^{-\alpha} + O(n^{-2\alpha}) = 2^{-\alpha} \cdot \frac{I_{2n} - I_n}{2^\alpha - 1} + O(n^{-2\alpha}).
Simplifying: \int_a^b f - I_{2n} \approx \frac{I_{2n} - I_n}{2^\alpha - 1}.
This formula estimates the error in I_{2n} using only the computed values I_n and I_{2n}, without knowing the exact integral. This is the foundation of adaptive quadrature algorithms. \square
Applying adaptive error estimation. For Simpson’s rule, \alpha = 4, so 2^\alpha - 1 = 15.
Given S_4 = 1.3333 and S_8 = 1.3334: \text{Estimated error in } S_8 \approx \frac{S_8 - S_4}{15} = \frac{0.0001}{15} \approx 6.7 \times 10^{-6}.
This estimate tells us that S_8 is accurate to about 5-6 decimal places. In adaptive quadrature, we would compare this estimated error to our tolerance \varepsilon. If 6.7 \times 10^{-6} < \varepsilon, we accept S_8. If not, we compute S_{16} and repeat.
Note that we never need the exact value of \int_a^b f to decide when to stop. The difference between successive refinements tells us how close we are. This is how numerical integration libraries like
scipy.integrate.quadwork internally. \squareDetermining required subdivisions. By Theorem 13.2 with M = 24, [a,b] = [0,1]: \left|\int_0^1 f - S_n\right| \leq \frac{(1-0)^5}{180n^4} \cdot 24 = \frac{24}{180n^4} = \frac{2}{15n^4}.
We require \frac{2}{15n^4} \leq 10^{-6}, so: n^4 \geq \frac{2 \times 10^6}{15} = \frac{200000}{1.5} \approx 133333.33.
Taking fourth roots: n \geq (133333.33)^{1/4} \approx 19.13.
Since n must be even for Simpson’s rule (we need pairs of subintervals), the minimum is n = 20.
With n = 20, we achieve: \text{Error} \leq \frac{2}{15 \cdot 20^4} = \frac{2}{15 \cdot 160000} = \frac{2}{2400000} = \frac{1}{1200000} \approx 8.3 \times 10^{-7} < 10^{-6}.
This calculation shows that Simpson’s rule is highly efficient: only 21 function evaluations (at points x_0, x_1, \ldots, x_{20}) achieve six-digit accuracy, provided f is sufficiently smooth (C^4 with bounded fourth derivative). This is why Simpson’s rule became the standard method in pre-computer numerical analysis. \square