11 Orthogonality and Projections
11.1 The Problem of Decomposition
The previous chapter equipped vector spaces with inner products, introducing notions of length, angle, and orthogonality. We can now measure \|v\|, determine when u \perp v, and quantify alignment via \langle u, v \rangle. But we have not yet exploited this geometric structure systematically.
Consider a fundamental question: given a subspace \mathcal{W} \subseteq \mathcal{V} and a vector v \in \mathcal{V}, how do we decompose v into components parallel and perpendicular to \mathcal{W}? In \mathbb{R}^3, if \mathcal{W} is a plane through the origin, every vector v splits uniquely as v = w + u where w \in \mathcal{W} lies in the plane and u \perp \mathcal{W} is perpendicular to it. This decomposition is geometric and coordinate-free—it depends only on the inner product structure.
Such decompositions are ubiquitous. In data analysis, principal component analysis projects high-dimensional data onto subspaces of maximal variance. In signal processing, filtering extracts components in frequency bands by projecting onto subspaces of sinusoids. In differential equations, Fourier series decompose functions into orthogonal harmonics. In statistics, linear regression finds the best-fit line by projecting data onto a subspace of linear functions.
The projection theorem (developed in Section 11.4) establishes that every finite-dimensional subspace \mathcal{W} of an inner product space admits an orthogonal complement \mathcal{W}^\perp, and every vector decomposes uniquely as v = w + u with w \in \mathcal{W} and u \in \mathcal{W}^\perp. The component w is the orthogonal projection of v onto \mathcal{W}—the closest point in \mathcal{W} to v.
To compute projections efficiently, we require orthonormal bases—bases where vectors have unit length and are pairwise perpendicular. The Gram-Schmidt process (Section 11.6) systematically constructs such bases from arbitrary ones. This algorithm underpins the QR decomposition (Section 11.7), a matrix factorization expressing any matrix as a product of an orthogonal matrix and an upper triangular matrix. The QR decomposition is the foundation for numerical algorithms in least squares, eigenvalue computation, and solving systems of equations.
This chapter develops these ideas systematically. We begin by studying orthogonal and orthonormal sets, establish the existence of orthogonal complements, prove the projection theorem, derive formulas for orthogonal projections, present the Gram-Schmidt algorithm, develop the QR factorization, and conclude with the application to least squares approximation—finding the best approximate solution to an overdetermined system Ax = b.
Throughout, we assume \mathcal{V} is a finite-dimensional inner product space over \mathbb{R} or \mathbb{C}. Results extend to infinite-dimensional Hilbert spaces with appropriate care regarding convergence, but we focus on the finite-dimensional setting where all sums are finite and all subspaces are closed.
11.2 Orthogonal and Orthonormal Sets
Recall from the previous chapter that vectors u, v \in \mathcal{V} are orthogonal, written u \perp v, if \langle u, v \rangle = 0. We now study collections of mutually orthogonal vectors.
Definition 11.1 (Orthogonal set) A set \{v_1, \ldots, v_k\} \subset \mathcal{V} is orthogonal if v_i \perp v_j for all i \neq j. It is orthonormal if additionally \|v_i\| = 1 for all i.
An orthonormal set satisfies \langle v_i, v_j \rangle = \delta_{ij}, where \delta_{ij} is the Kronecker delta: \delta_{ij} = \begin{cases} 1 & \text{if } i = j \\ 0 & \text{if } i \neq j \end{cases}.
The standard basis \{e_1, \ldots, e_n\} of \mathbb{R}^n is orthonormal with respect to the standard inner product. In C([−1,1]) with \langle f, g \rangle = \int_{-1}^1 f g, the functions \{1, x, x^2, \ldots\} are orthogonal but not orthonormal—the Legendre polynomials, obtained by orthonormalizing this set, form an orthonormal basis.
Theorem 11.1 Every orthogonal set of nonzero vectors is linearly independent.
Proof. Let \{v_1, \ldots, v_k\} be orthogonal with each v_i \neq 0. Suppose \sum_{i=1}^k c_i v_i = 0. Taking the inner product with v_j on both sides, \left\langle \sum_{i=1}^k c_i v_i, v_j \right\rangle = \langle 0, v_j \rangle = 0. By linearity, \sum_{i=1}^k c_i \langle v_i, v_j \rangle = 0. Since \langle v_i, v_j \rangle = 0 for i \neq j, this reduces to c_j \langle v_j, v_j \rangle = 0. Since v_j \neq 0, we have \langle v_j, v_j \rangle = \|v_j\|^2 > 0, forcing c_j = 0. This holds for all j, so the set is independent. \square
Orthogonality is thus stronger than independence: orthogonal vectors are not merely linearly independent—they are geometrically perpendicular. This rigidity simplifies many computations.
Theorem 11.2 If \{v_1, \ldots, v_k\} is orthogonal, then \left\|\sum_{i=1}^k v_i\right\|^2 = \sum_{i=1}^k \|v_i\|^2.
Proof. Expand the norm: \left\|\sum_{i=1}^k v_i\right\|^2 = \left\langle \sum_i v_i, \sum_j v_j \right\rangle = \sum_{i,j} \langle v_i, v_j \rangle. Since \langle v_i, v_j \rangle = 0 for i \neq j, only diagonal terms survive: \sum_{i,j} \langle v_i, v_j \rangle = \sum_{i=1}^k \langle v_i, v_i \rangle = \sum_{i=1}^k \|v_i\|^2. \quad \square
This is the Pythagorean theorem for orthogonal vectors, generalizing the familiar identity \|u + v\|^2 = \|u\|^2 + \|v\|^2 when u \perp v.
11.2.1 Coordinates in Orthonormal Bases
Orthonormal bases dramatically simplify coordinate computations.
Theorem 11.3 Let \mathcal{B} = \{e_1, \ldots, e_n\} be an orthonormal basis of \mathcal{V}. For any v \in \mathcal{V}, v = \sum_{i=1}^n \langle v, e_i \rangle e_i. That is, the i-th coordinate of v in basis \mathcal{B} is \langle v, e_i \rangle.
Proof. Write v = \sum_{i=1}^n c_i e_i for some scalars c_i. Taking the inner product with e_j, \langle v, e_j \rangle = \left\langle \sum_i c_i e_i, e_j \right\rangle = \sum_i c_i \langle e_i, e_j \rangle = \sum_i c_i \delta_{ij} = c_j. \quad \square
This result shows that in an orthonormal basis, extracting coordinates is trivial: compute inner products with basis vectors. No system of equations, no Gaussian elimination—the orthonormality makes \langle v, e_i \rangle immediately give the i-th coordinate.
Compare this to an arbitrary basis \{v_1, \ldots, v_n\}, where finding coordinates of w requires solving \sum c_i v_i = w—a linear system. Orthonormal bases eliminate this computational burden.
Theorem 11.4 If \mathcal{B} = \{e_1, \ldots, e_n\} is orthonormal and v = \sum_{i=1}^n c_i e_i, then \|v\|^2 = \sum_{i=1}^n |c_i|^2.
Proof. By Theorem 11.2 applied to v = \sum c_i e_i where the c_i e_i are orthogonal (since the e_i are orthogonal), \|v\|^2 = \sum_{i=1}^n \|c_i e_i\|^2 = \sum_{i=1}^n |c_i|^2 \|e_i\|^2 = \sum_{i=1}^n |c_i|^2. \quad \square
This is Parseval’s identity: the norm squared equals the sum of squared coordinate magnitudes. In \mathbb{R}^n with the standard basis, this is \|x\|^2 = \sum x_i^2. In Fourier analysis, it states that the energy of a signal equals the sum of energies in its frequency components.
11.2.2 Orthonormal Bases and Matrix Representations
Let \mathcal{B} = \{e_1, \ldots, e_n\} be an orthonormal basis. The Gram matrix G with g_{ij} = \langle e_i, e_j \rangle is G = I_n, the identity matrix. This reflects that inner products in orthonormal coordinates take the standard form: \langle u, v \rangle = [u]_{\mathcal{B}}^T \,\overline{[v]_{\mathcal{B}}}, where \overline{[v]_{\mathcal{B}}} denotes the coordinatewise complex conjugate (trivial over \mathbb{R}).
Conversely, if G = I_n for some basis, that basis is orthonormal. This provides a computational test: a basis is orthonormal if and only if its Gram matrix is the identity.
11.3 Orthogonal Complements
Given a subspace \mathcal{W} \subseteq \mathcal{V}, we define the set of all vectors orthogonal to every vector in \mathcal{W}.
Definition 11.2 (Orthogonal complement) Let \mathcal{W} \subseteq \mathcal{V} be a subspace. The orthogonal complement of \mathcal{W} is \mathcal{W}^\perp = \{v \in \mathcal{V} : \langle v, w \rangle = 0 \text{ for all } w \in \mathcal{W}\}.
The notation \mathcal{W}^\perp (read “\mathcal{W} perp”) denotes the set of vectors perpendicular to the entire subspace \mathcal{W}. To belong to \mathcal{W}^\perp, a vector must be orthogonal to every vector in \mathcal{W}, not just to a spanning set or basis.
Examples.
In \mathbb{R}^3, let \mathcal{W} = \operatorname{span}\{(1,0,0)\}, the x-axis. Then \mathcal{W}^\perp = \{(0,y,z) : y,z \in \mathbb{R}\}, the yz-plane.
In \mathbb{R}^3, let \mathcal{W} be the xy-plane, spanned by (1,0,0) and (0,1,0). Then \mathcal{W}^\perp = \operatorname{span}\{(0,0,1)\}, the z-axis.
If \mathcal{W} = \{0\}, then \mathcal{W}^\perp = \mathcal{V} since every vector is orthogonal to 0.
If \mathcal{W} = \mathcal{V}, then \mathcal{W}^\perp = \{0\} by non-degeneracy of the inner product.
Theorem 11.5 \mathcal{W}^\perp is a subspace of \mathcal{V}.
Proof. We verify the subspace axioms.
Contains zero: \langle 0, w \rangle = 0 for all w \in \mathcal{W}, so 0 \in \mathcal{W}^\perp.
Closed under addition: Let u, v \in \mathcal{W}^\perp. For any w \in \mathcal{W}, \langle u + v, w \rangle = \langle u, w \rangle + \langle v, w \rangle = 0 + 0 = 0, so u + v \in \mathcal{W}^\perp.
Closed under scalar multiplication: Let v \in \mathcal{W}^\perp and c \in \mathbb{F}. For any w \in \mathcal{W}, \langle cv, w \rangle = c\langle v, w \rangle = c \cdot 0 = 0, so cv \in \mathcal{W}^\perp. \square
Theorem 11.6 \mathcal{W} \cap \mathcal{W}^\perp = \{0\}.
Proof. Suppose v \in \mathcal{W} \cap \mathcal{W}^\perp. Then v \in \mathcal{W} and v \perp w for all w \in \mathcal{W}. Taking w = v gives \langle v, v \rangle = 0, so \|v\|^2 = 0, forcing v = 0 by positive definiteness. \square
The orthogonal complement satisfies several natural properties.
Theorem 11.7 Let \mathcal{W}, \mathcal{U} \subseteq \mathcal{V} be subspaces.
(\mathcal{W}^\perp)^\perp = \mathcal{W} when \dim \mathcal{V} < \infty
If \mathcal{U} \subseteq \mathcal{W}, then \mathcal{W}^\perp \subseteq \mathcal{U}^\perp
(\mathcal{W} + \mathcal{U})^\perp = \mathcal{W}^\perp \cap \mathcal{U}^\perp
(\mathcal{W} \cap \mathcal{U})^\perp \supseteq \mathcal{W}^\perp + \mathcal{U}^\perp
Proof.
Clearly \mathcal{W} \subseteq (\mathcal{W}^\perp)^\perp since any w \in \mathcal{W} is orthogonal to everything in \mathcal{W}^\perp. By the projection theorem (Theorem 11.8 below), \dim \mathcal{W} + \dim \mathcal{W}^\perp = \dim \mathcal{V}. Applying this to \mathcal{W}^\perp gives \dim (\mathcal{W}^\perp)^\perp = \dim \mathcal{V} - \dim \mathcal{W}^\perp = \dim \mathcal{W}. Since \mathcal{W} \subseteq (\mathcal{W}^\perp)^\perp and they have the same dimension, \mathcal{W} = (\mathcal{W}^\perp)^\perp.
If v \in \mathcal{W}^\perp, then \langle v, w \rangle = 0 for all w \in \mathcal{W}. Since \mathcal{U} \subseteq \mathcal{W}, this implies \langle v, u \rangle = 0 for all u \in \mathcal{U}, so v \in \mathcal{U}^\perp.
A vector v is orthogonal to \mathcal{W} + \mathcal{U} if and only if it is orthogonal to every vector of the form w + u with w \in \mathcal{W} and u \in \mathcal{U}. By linearity, this holds if and only if v is orthogonal to both \mathcal{W} and \mathcal{U}, i.e., v \in \mathcal{W}^\perp \cap \mathcal{U}^\perp.
If v \in \mathcal{W}^\perp + \mathcal{U}^\perp, write v = w' + u' with w' \in \mathcal{W}^\perp and u' \in \mathcal{U}^\perp. For any z \in \mathcal{W} \cap \mathcal{U}, we have \langle v, z \rangle = \langle w', z \rangle + \langle u', z \rangle = 0 + 0 = 0, so v \in (\mathcal{W} \cap \mathcal{U})^\perp. \square
Property (a) states that taking the orthogonal complement twice returns to the original subspace. This “double complement” property is characteristic of orthogonality and fails for more general annihilators.
Property (c) shows that orthogonal complements reverse sums to intersections. This duality is a manifestation of the contravariance of the orthogonal complement operation.
11.4 The Projection Theorem
We now establish the fundamental decomposition result: every vector in a finite-dimensional inner product space splits uniquely into components inside and orthogonal to any given subspace.
Theorem 11.8 (Projection theorem) Let \mathcal{W} be a finite-dimensional subspace of an inner product space \mathcal{V}. Then \mathcal{V} = \mathcal{W} \oplus \mathcal{W}^\perp. That is, every v \in \mathcal{V} can be written uniquely as v = w + u with w \in \mathcal{W} and u \in \mathcal{W}^\perp.
Proof. We first establish existence of the decomposition, then uniqueness.
Existence. Let \{e_1, \ldots, e_k\} be an orthonormal basis of \mathcal{W} (such a basis exists by the Gram-Schmidt process, developed in Section 11.6, or by normalizing an arbitrary basis if one wishes to defer Gram-Schmidt).
For any v \in \mathcal{V}, define w = \sum_{i=1}^k \langle v, e_i \rangle e_i, \quad u = v - w. Clearly w \in \mathcal{W} since it is a linear combination of basis vectors of \mathcal{W}. We claim u \in \mathcal{W}^\perp.
For any j \in \{1, \ldots, k\}, compute \langle u, e_j \rangle = \langle v - w, e_j \rangle = \langle v, e_j \rangle - \left\langle \sum_i \langle v, e_i \rangle e_i, e_j \right\rangle = \langle v, e_j \rangle - \sum_i \langle v, e_i \rangle \langle e_i, e_j \rangle. Since \langle e_i, e_j \rangle = \delta_{ij}, the sum collapses to \langle u, e_j \rangle = \langle v, e_j \rangle - \langle v, e_j \rangle = 0. Thus u is orthogonal to every basis vector of \mathcal{W}. Since \{e_1, \ldots, e_k\} spans \mathcal{W}, and the inner product is linear, u is orthogonal to every vector in \mathcal{W}, i.e., u \in \mathcal{W}^\perp.
Uniqueness. Suppose v = w_1 + u_1 = w_2 + u_2 with w_i \in \mathcal{W} and u_i \in \mathcal{W}^\perp. Then w_1 - w_2 = u_2 - u_1. The left side belongs to \mathcal{W} (since \mathcal{W} is a subspace), and the right side belongs to \mathcal{W}^\perp (since \mathcal{W}^\perp is a subspace). By Theorem 11.6, the only vector in both is 0, so w_1 = w_2 and u_1 = u_2. \square
The projection theorem is one of the most important results in linear algebra. It establishes that finite-dimensional subspaces admit orthogonal complements with which they decompose the entire space as a direct sum. This is not obvious a priori—there are many ways to complement a subspace, but the orthogonal complement is the unique one defined by the inner product structure.
Corollary 11.1 If \mathcal{W} is a finite-dimensional subspace of an inner product space \mathcal{V} with \dim \mathcal{V} < \infty, then \dim \mathcal{W} + \dim \mathcal{W}^\perp = \dim \mathcal{V}.
Proof. By Theorem 11.8, \mathcal{V} = \mathcal{W} \oplus \mathcal{W}^\perp. By Corollary 3.2 from Chapter 2, \dim \mathcal{V} = \dim \mathcal{W} + \dim \mathcal{W}^\perp. \square
This dimension formula is the inner product space analog of the rank-nullity theorem. It states that the dimensions of a subspace and its orthogonal complement always sum to the dimension of the ambient space.
11.5 Orthogonal Projections
The decomposition v = w + u provided by Theorem 11.8 yields a map v \mapsto w sending each vector to its component in \mathcal{W}. This map is the orthogonal projection onto \mathcal{W}.
Definition 11.3 (Orthogonal projection operator) Let \mathcal{W} be a finite-dimensional subspace of \mathcal{V}. The orthogonal projection onto \mathcal{W} is the linear map P_{\mathcal{W}} : \mathcal{V} \to \mathcal{V} defined by: if v = w + u with w \in \mathcal{W} and u \in \mathcal{W}^\perp, then P_{\mathcal{W}}(v) = w.
By Theorem 11.8, the decomposition is unique, so P_{\mathcal{W}} is well-defined. Linearity is straightforward: if v = w + u and v' = w' + u', then av + bv' = (aw + bw') + (au + bu') where aw + bw' \in \mathcal{W} and au + bu' \in \mathcal{W}^\perp, so P_{\mathcal{W}}(av + bv') = aw + bw' = aP_{\mathcal{W}}(v) + bP_{\mathcal{W}}(v').
Theorem 11.9 The orthogonal projection P_{\mathcal{W}} : \mathcal{V} \to \mathcal{V} satisfies:
P_{\mathcal{W}}^2 = P_{\mathcal{W}} (idempotence)
\operatorname{im}(P_{\mathcal{W}}) = \mathcal{W}
\ker(P_{\mathcal{W}}) = \mathcal{W}^\perp
P_{\mathcal{W}}(v) = v if and only if v \in \mathcal{W}
P_{\mathcal{W}}(v) = 0 if and only if v \in \mathcal{W}^\perp
Proof.
Let v = w + u with w \in \mathcal{W} and u \in \mathcal{W}^\perp. Then P_{\mathcal{W}}(v) = w \in \mathcal{W}. Since w is already in \mathcal{W}, its decomposition is w = w + 0 with 0 \in \mathcal{W}^\perp, so P_{\mathcal{W}}(w) = w. Thus P_{\mathcal{W}}^2(v) = P_{\mathcal{W}}(P_{\mathcal{W}}(v)) = P_{\mathcal{W}}(w) = w = P_{\mathcal{W}}(v).
Clearly \operatorname{im}(P_{\mathcal{W}}) \subseteq \mathcal{W} since P_{\mathcal{W}}(v) \in \mathcal{W} for all v. Conversely, for any w \in \mathcal{W}, we have P_{\mathcal{W}}(w) = w by part (d) below, so w \in \operatorname{im}(P_{\mathcal{W}}).
If v \in \mathcal{W}^\perp, then v = 0 + v is the decomposition (since 0 \in \mathcal{W} and v \in \mathcal{W}^\perp), so P_{\mathcal{W}}(v) = 0. Conversely, if P_{\mathcal{W}}(v) = 0, writing v = w + u gives w = 0, so v = u \in \mathcal{W}^\perp.
and (e) follow from the definitions. \square
Idempotence (P^2 = P) characterizes projection operators in general. Applied once, P_{\mathcal{W}} extracts the \mathcal{W}-component; applying again does nothing since we are already in \mathcal{W}.
11.5.1 The Projection Formula
To compute P_{\mathcal{W}}(v) explicitly, we need a basis of \mathcal{W}. An orthonormal basis simplifies the formula dramatically.
Theorem 11.10 Let \{e_1, \ldots, e_k\} be an orthonormal basis of \mathcal{W}. Then P_{\mathcal{W}}(v) = \sum_{i=1}^k \langle v, e_i \rangle e_i.
Proof. This was established in the proof of Theorem 11.8. The vector w = \sum \langle v, e_i \rangle e_i satisfies v - w \perp \mathcal{W}, so by uniqueness of the decomposition, w = P_{\mathcal{W}}(v). \square
This formula is remarkable: to project onto \mathcal{W}, compute the inner product of v with each orthonormal basis vector, then form the linear combination using these inner products as coefficients. No matrix inversion, no system of equations—just inner products and sums.
If the basis of \mathcal{W} is not orthonormal, the formula is more complicated. Let \{v_1, \ldots, v_k\} be an arbitrary basis of \mathcal{W}, and let G be the Gram matrix with g_{ij} = \langle v_i, v_j \rangle.
Theorem 11.11 Let \{v_1, \ldots, v_k\} be a basis of \mathcal{W} and G the Gram matrix. Then P_{\mathcal{W}}(v) = \sum_{i=1}^k c_i v_i, where the coefficients c = (c_1, \ldots, c_k)^T satisfy Gc = \begin{pmatrix} \langle v, v_1 \rangle \\ \vdots \\ \langle v, v_k \rangle \end{pmatrix}.
Proof. Write P_{\mathcal{W}}(v) = \sum c_i v_i for some coefficients c_i. Since v - P_{\mathcal{W}}(v) \in \mathcal{W}^\perp, we have \langle v - P_{\mathcal{W}}(v), v_j \rangle = 0 for all j. Expanding, \langle v, v_j \rangle - \left\langle \sum_i c_i v_i, v_j \right\rangle = 0. By linearity, \langle v, v_j \rangle = \sum_i c_i \langle v_i, v_j \rangle = \sum_i c_i g_{ji}. This gives the system G c = (\langle v, v_1 \rangle, \ldots, \langle v, v_k \rangle)^T. Since \{v_1, \ldots, v_k\} is a basis, G is positive definite and invertible, so c = G^{-1} (\langle v, v_1 \rangle, \ldots, \langle v, v_k \rangle)^T. \square
The general formula requires solving a linear system and inverting the Gram matrix. This is computationally expensive for large k. Orthonormal bases eliminate this cost entirely—hence the value of the Gram-Schmidt process.
11.5.2 Best Approximation Property
The orthogonal projection P_{\mathcal{W}}(v) is not merely one decomposition of v—it is the closest point in \mathcal{W} to v.
Theorem 11.12 (Best approximation theorem) Let \mathcal{W} be a finite-dimensional subspace of \mathcal{V} and v \in \mathcal{V}. Then P_{\mathcal{W}}(v) is the unique vector in \mathcal{W} minimizing \|v - w\| over all w \in \mathcal{W}.
Proof. Write v = P_{\mathcal{W}}(v) + u where u \in \mathcal{W}^\perp. For any w \in \mathcal{W}, \|v - w\|^2 = \|(P_{\mathcal{W}}(v) + u) - w\|^2 = \|(P_{\mathcal{W}}(v) - w) + u\|^2. Since P_{\mathcal{W}}(v) - w \in \mathcal{W} and u \in \mathcal{W}^\perp, these are orthogonal. By the Pythagorean theorem, \|v - w\|^2 = \|P_{\mathcal{W}}(v) - w\|^2 + \|u\|^2 \ge \|u\|^2, with equality if and only if \|P_{\mathcal{W}}(v) - w\| = 0, i.e., w = P_{\mathcal{W}}(v). Thus P_{\mathcal{W}}(v) uniquely minimizes the distance. \square
This theorem justifies calling P_{\mathcal{W}} the orthogonal projection: it projects v onto \mathcal{W} in the direction perpendicular to \mathcal{W}, landing at the nearest point.
Applications abound. In data fitting, we approximate data by projecting onto a subspace of simple functions. In signal processing, we filter by projecting onto frequency bands. In machine learning, we reduce dimension by projecting onto principal components.
11.6 The Gram-Schmidt Process
Given an arbitrary basis, we seek to construct an orthonormal basis spanning the same subspace. The Gram-Schmidt process accomplishes this systematically.
Theorem 11.13 (Gram-Schmidt orthogonalization) Let \{v_1, \ldots, v_k\} be linearly independent vectors in an inner product space. There exists an orthonormal set \{e_1, \ldots, e_k\} such that \operatorname{span}\{e_1, \ldots, e_j\} = \operatorname{span}\{v_1, \ldots, v_j\} for all j = 1, \ldots, k.
Proof (algorithm). We construct the e_i inductively.
Base case (j=1): Set e_1 = v_1 / \|v_1\|. Then \|e_1\| = 1 and \operatorname{span}\{e_1\} = \operatorname{span}\{v_1\}.
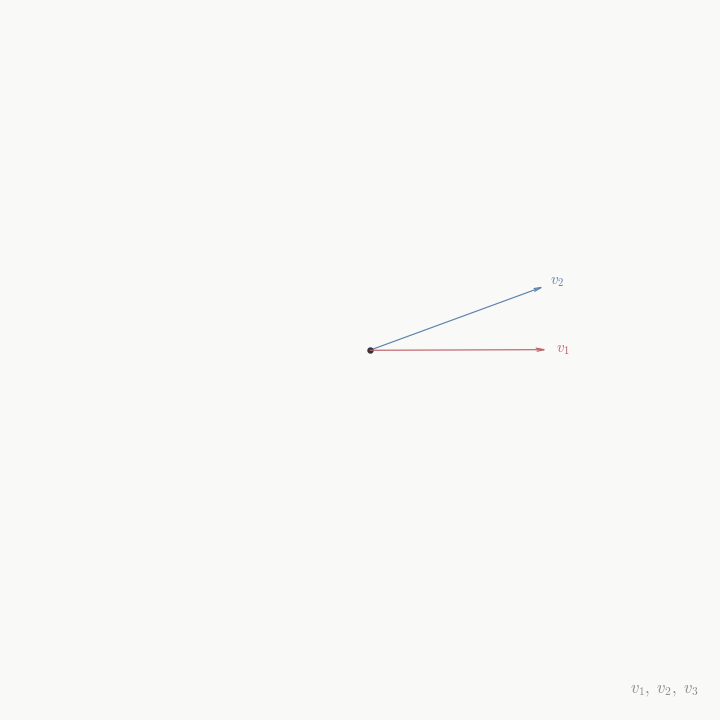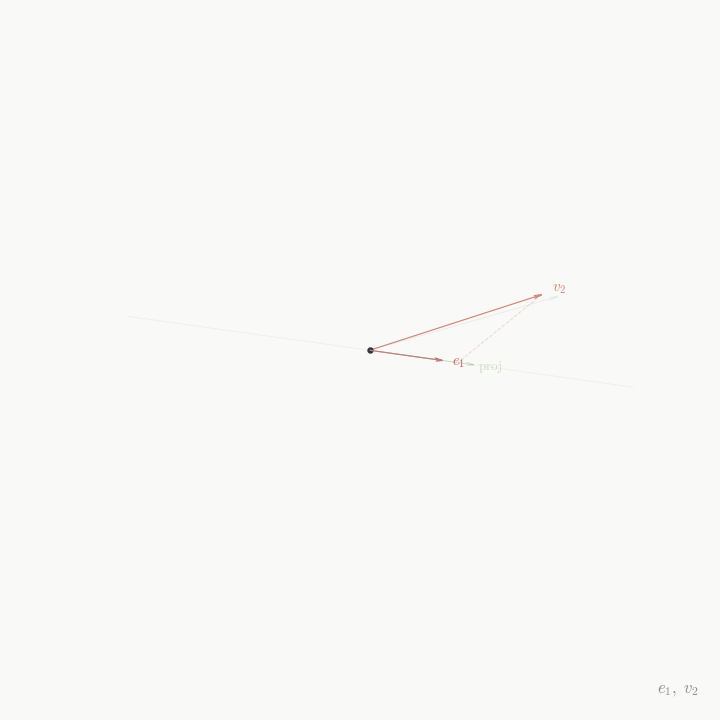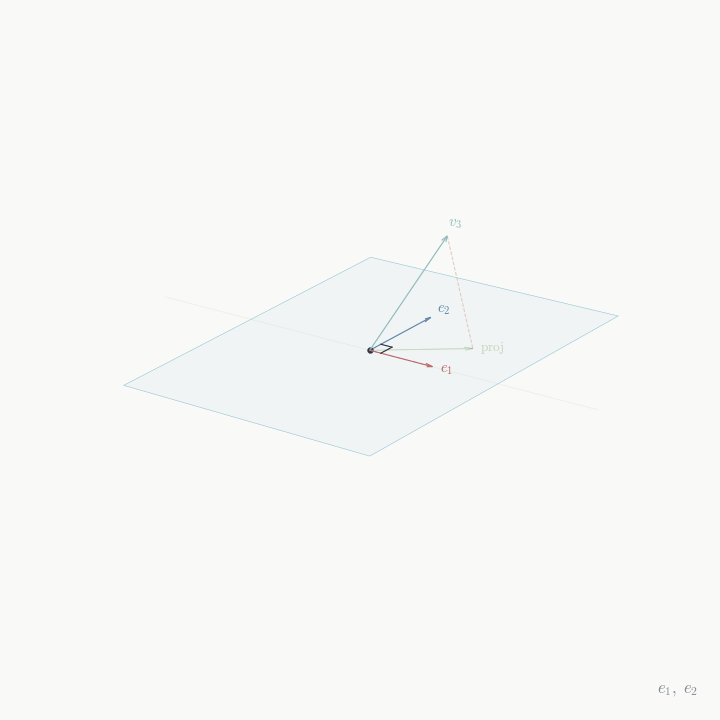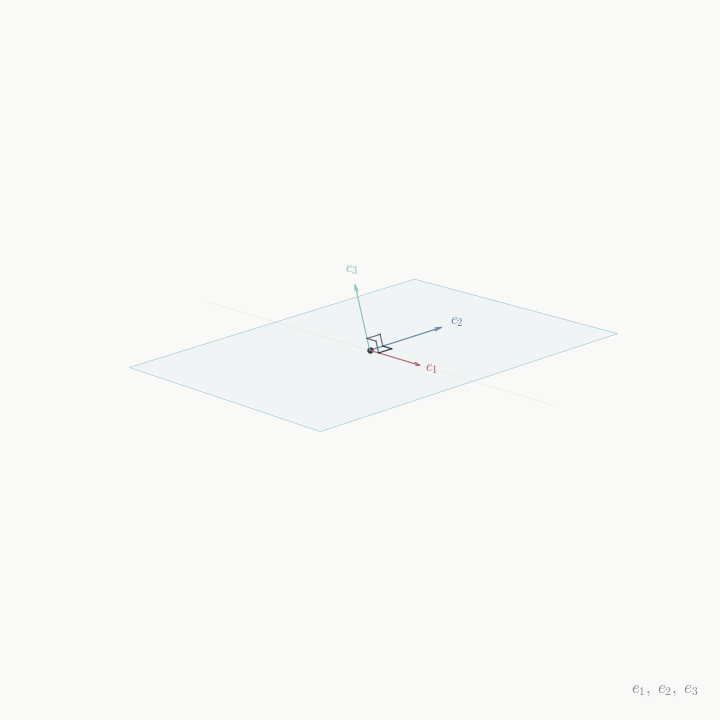
Inductive step: Assume we have constructed e_1, \ldots, e_{j-1} orthonormal with \operatorname{span}\{e_1, \ldots, e_{j-1}\} = \operatorname{span}\{v_1, \ldots, v_{j-1}\}. Define u_j = v_j - \sum_{i=1}^{j-1} \langle v_j, e_i \rangle e_i. This subtracts from v_j its projection onto \operatorname{span}\{e_1, \ldots, e_{j-1}\}, leaving the component orthogonal to that span.
We verify u_j \perp e_\ell for \ell < j: \langle u_j, e_\ell \rangle = \langle v_j, e_\ell \rangle - \sum_{i=1}^{j-1} \langle v_j, e_i \rangle \langle e_i, e_\ell \rangle = \langle v_j, e_\ell \rangle - \langle v_j, e_\ell \rangle = 0.
Since v_j \notin \operatorname{span}\{v_1, \ldots, v_{j-1}\} = \operatorname{span}\{e_1, \ldots, e_{j-1}\} (by linear independence), we have u_j \neq 0. Set e_j = \frac{u_j}{\|u_j\|}. Then \|e_j\| = 1, e_j \perp e_i for all i < j, and \operatorname{span}\{e_1, \ldots, e_j\} = \operatorname{span}\{v_1, \ldots, v_j\} since e_j is a linear combination of v_j and e_1, \ldots, e_{j-1}, which are linear combinations of v_1, \ldots, v_{j-1}. \square
The Gram-Schmidt process is constructive: given v_1, \ldots, v_k, compute e_1, \ldots, e_k by the explicit formulas above. Each step involves computing inner products and vector sums—no matrix inversions.
Corollary 11.2 Every finite-dimensional inner product space has an orthonormal basis.
Proof. Let \dim \mathcal{V} = n and choose any basis \{v_1, \ldots, v_n\}. Apply Gram-Schmidt to obtain an orthonormal set \{e_1, \ldots, e_n\} with \operatorname{span}\{e_1, \ldots, e_n\} = \operatorname{span}\{v_1, \ldots, v_n\} = \mathcal{V}. Since \{e_1, \ldots, e_n\} is orthonormal, it is linearly independent by Theorem 11.1, and spanning \mathcal{V} with n independent vectors makes it a basis. \square
11.6.1 Modified Gram-Schmidt
The classical Gram-Schmidt algorithm can suffer from numerical instability in finite-precision arithmetic when vectors are nearly linearly dependent. The modified Gram-Schmidt algorithm reorders the computations for better stability.
In classical Gram-Schmidt, we compute u_j = v_j - \sum_{i=1}^{j-1} \langle v_j, e_i \rangle e_i. In modified Gram-Schmidt, we update v_j step-by-step: \begin{align*} u_j^{(1)} &= v_j - \langle v_j, e_1 \rangle e_1, \\ u_j^{(2)} &= u_j^{(1)} - \langle u_j^{(1)}, e_2 \rangle e_2, \\ &\vdots \\ u_j &= u_j^{(j-1)} - \langle u_j^{(j-1)}, e_{j-1} \rangle e_{j-1}. \end{align*} The final result is identical mathematically but more stable numerically. This variant is preferred in practical implementations.
11.7 QR Decomposition
The Gram-Schmidt process yields a useful matrix factorization.
Theorem 11.14 (QR decomposition) Let A \in M_{m \times n}(\mathbb{F}) with m \ge n have linearly independent columns. Then A = QR where Q \in M_{m \times n}(\mathbb{F}) has orthonormal columns and R \in M_{n \times n}(\mathbb{F}) is upper triangular with positive diagonal entries.
Proof. Let a_1, \ldots, a_n be the columns of A, viewed as vectors in \mathbb{F}^m. These are linearly independent by assumption. Apply Gram-Schmidt to obtain orthonormal vectors q_1, \ldots, q_n with \operatorname{span}\{q_1, \ldots, q_j\} = \operatorname{span}\{a_1, \ldots, a_j\} for all j.
Since a_j \in \operatorname{span}\{q_1, \ldots, q_j\}, we can write a_j = r_{1j} q_1 + r_{2j} q_2 + \cdots + r_{jj} q_j for some coefficients r_{ij}. By orthonormality, r_{ij} = \langle a_j, q_i \rangle for i \le j. Define r_{ij} = 0 for i > j.
Let Q be the m \times n matrix with columns q_1, \ldots, q_n, and let R be the n \times n upper triangular matrix with entries r_{ij}. Then A = QR by construction.
The diagonal entries of R are r_{jj} = \|u_j\| from the Gram-Schmidt process, which are positive since u_j \neq 0. \square
The QR decomposition expresses A as a product of an orthogonal-column matrix Q and an upper triangular matrix R. The orthonormal columns of Q form a basis for \operatorname{Col}(A), and R encodes the change-of-basis coefficients.
Corollary 11.3 If A \in M_n(\mathbb{F}) is invertible, then A = QR where Q is orthogonal (unitary in the complex case) and R is upper triangular with positive diagonal entries.
Proof. Apply Theorem 11.14. Since A is square and invertible, its columns form a basis of \mathbb{F}^n, so the Gram-Schmidt process produces n orthonormal vectors forming an orthonormal basis. Thus Q is square with orthonormal columns, making it orthogonal (unitary). \square
11.7.1 Computing QR via Gram-Schmidt
Given A = (a_1 \mid \cdots \mid a_n), apply Gram-Schmidt:
Set q_1 = a_1 / \|a_1\| and r_{11} = \|a_1\|.
For j = 2, \ldots, n:
Compute u_j = a_j - \sum_{i=1}^{j-1} \langle a_j, q_i \rangle q_i.
Set r_{ij} = \langle a_j, q_i \rangle for i = 1, \ldots, j-1.
Set r_{jj} = \|u_j\|.
Set q_j = u_j / \|u_j\|.
The matrices Q = (q_1 \mid \cdots \mid q_n) and R = (r_{ij}) satisfy A = QR.
11.7.2 Applications of QR
The QR decomposition is fundamental in numerical linear algebra:
Solving linear systems: Ax = b becomes QRx = b, so Rx = Q^T b (or Q^* b in the complex case). Since R is triangular, back-substitution solves this efficiently.
Least squares: The normal equation A^T A x = A^T b is numerically unstable. The QR approach solves Rx = Q^T b directly, avoiding forming A^T A.
Eigenvalue algorithms: The QR iteration repeatedly computes A_k = Q_k R_k and sets A_{k+1} = R_k Q_k. This converges to a triangular (or block-triangular) matrix revealing eigenvalues.
Orthogonal basis for range: The columns of Q provide an orthonormal basis for \operatorname{Col}(A).
11.8 Orthogonal and Unitary Matrices
Matrices with orthonormal columns preserve the geometric structure induced by the inner product. They are the linear-algebraic manifestation of isometries—transformations preserving distances and angles.
Definition 11.4 (Orthogonal and unitary matrices) A real matrix Q \in M_n(\mathbb{R}) is orthogonal if Q^T Q = I_n. A complex matrix U \in M_n(\mathbb{C}) is unitary if U^* U = I_n, where U^* = \overline{U}^T is the conjugate transpose.
Equivalently, a matrix is orthogonal (or unitary) if its columns form an orthonormal basis of \mathbb{R}^n (or \mathbb{C}^n). The condition Q^T Q = I states that \langle q_i, q_j \rangle = \delta_{ij} where q_i denotes the i-th column.
Examples.
Rotation matrices in \mathbb{R}^2: For \theta \in \mathbb{R}, Q = \begin{pmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{pmatrix} is orthogonal. It rotates vectors counterclockwise by angle \theta.
Reflection matrices: The matrix Q = \begin{pmatrix} 1 & 0 \\ 0 & -1 \end{pmatrix} reflects across the x-axis. More generally, reflection across a hyperplane perpendicular to unit vector u is given by Q = I - 2uu^T.
Permutation matrices: Matrices with exactly one 1 in each row and column (and zeros elsewhere) are orthogonal. They permute the standard basis vectors.
Identity and negatives: I_n and -I_n are orthogonal.
Theorem 11.15 Let Q \in M_n(\mathbb{F}) be orthogonal (real case) or unitary (complex case). Then:
Q is invertible with Q^{-1} = Q^T (real) or Q^{-1} = Q^* (complex)
\|Qx\| = \|x\| for all x \in \mathbb{F}^n (isometry)
\langle Qx, Qy \rangle = \langle x, y \rangle for all x, y \in \mathbb{F}^n (preserves inner products)
|\det(Q)| = 1
The rows of Q also form an orthonormal set
Proof.
If Q^T Q = I, then Q is invertible with inverse Q^T. Multiplying Q^T Q = I on the right by Q^{-1} gives Q^T = Q^{-1}. The complex case is identical.
In the real case, \|Qx\|^2 = (Qx)^T (Qx) = x^T Q^T Q x = x^T I x = x^T x = \|x\|^2. In the complex case, \|Qx\|^2 = (Qx)^* (Qx) = x^* Q^* Q x = x^* x = \|x\|^2.
In the real case, \langle Qx, Qy \rangle = (Qx)^T (Qy) = x^T Q^T Q y = x^T y = \langle x, y \rangle. In the complex case, \langle Qx, Qy \rangle = (Qx)^* (Qy) = x^* Q^* Q y = x^* y = \langle x, y \rangle.
In the real case, taking determinants of Q^TQ = I gives \det(Q^T)\det(Q) = 1. Since \det(Q^T) = \det(Q), we get \det(Q)^2 = 1, so |\det(Q)| = 1. In the complex case, taking determinants of Q^*Q = I gives \det(Q^*)\det(Q) = 1. Since \det(Q^*) = \overline{\det(Q)} (as \det is conjugate-linear in the rows, and Q^* conjugate-transposes Q), we get |\det(Q)|^2 = 1, so |\det(Q)| = 1.
In the real case, from Q^TQ = I, since Q^T = Q^{-1}, also QQ^T = I. In the complex case, from Q^*Q = I, since Q^* = Q^{-1}, also QQ^* = I. In both cases the Gram matrix for the rows has (i,j)-entry \sum_k Q_{ik}\overline{Q_{jk}}, which is the (i,j)-entry of QQ^* (or QQ^T over \mathbb{R}), and this equals \delta_{ij}. \square
Property (b) shows orthogonal/unitary matrices preserve lengths—they are isometries. Property (c) shows they preserve inner products, hence angles. These transformations are rigid motions: rotations, reflections, and their compositions.
Property (d) constrains determinants: for real orthogonal matrices, \det(Q) = \pm 1. When \det(Q) = 1, Q represents a rotation (orientation-preserving); when \det(Q) = -1, Q represents a reflection or improper rotation (orientation-reversing). Unitary matrices satisfy |\det(U)| = 1, placing \det(U) on the unit circle in \mathbb{C}.
Theorem 11.16 The set of n \times n orthogonal matrices (or unitary matrices) forms a group under matrix multiplication.
Proof. We verify the group axioms.
Closure: If Q_1, Q_2 are orthogonal, then (Q_1 Q_2)^T (Q_1 Q_2) = Q_2^T Q_1^T Q_1 Q_2 = Q_2^T I Q_2 = Q_2^T Q_2 = I, so Q_1 Q_2 is orthogonal.
Identity: I_n is orthogonal since I^T I = I.
Inverses: If Q is orthogonal, then Q^{-1} = Q^T, and (Q^T)^T Q^T = Q Q^T = I, so Q^{-1} is orthogonal.
Associativity: Matrix multiplication is associative. \square
The orthogonal group O(n) consists of all n \times n real orthogonal matrices. The special orthogonal group SO(n) = \{Q \in O(n) : \det(Q) = 1\} consists of rotations. In the complex case, the unitary group U(n) and special unitary group SU(n) are defined analogously.
These groups are fundamental in geometry, physics, and representation theory. SO(3) describes rotations of three-dimensional space, central to classical mechanics. SU(2) is the double cover of SO(3), essential in quantum mechanics for describing spin. U(1) is the circle group, governing electromagnetic gauge transformations.
11.8.1 Orthogonal Matrices in Coordinates
Let T : \mathcal{V} \to \mathcal{V} be a linear operator on a finite-dimensional inner product space. If \mathcal{B} is an orthonormal basis, the matrix A = [T]_{\mathcal{B}} satisfies \langle T(v), T(w) \rangle = [T(v)]_{\mathcal{B}}^* [T(w)]_{\mathcal{B}} = ([v]_{\mathcal{B}}^* A^*) (A [w]_{\mathcal{B}}) = [v]_{\mathcal{B}}^* (A^* A) [w]_{\mathcal{B}}. If T preserves inner products—if \langle T(v), T(w) \rangle = \langle v, w \rangle for all v, w—then A^* A = I, so A is unitary (or orthogonal in the real case).
Theorem 11.17 Let T : \mathcal{V} \to \mathcal{V} be a linear operator on a finite-dimensional inner product space. The following are equivalent:
T preserves inner products: \langle T(v), T(w) \rangle = \langle v, w \rangle for all v, w
T preserves norms: \|T(v)\| = \|v\| for all v
If \mathcal{B} is any orthonormal basis, [T]_{\mathcal{B}} is orthogonal (or unitary)
T maps every orthonormal basis to an orthonormal basis
Proof.
\implies (ii): If \langle T(v), T(w) \rangle = \langle v, w \rangle, then taking w = v gives \|T(v)\|^2 = \|v\|^2.
\implies (i): Use the polarization identity. In the real case, \langle v, w \rangle = \frac{1}{4}(\|v+w\|^2 - \|v-w\|^2). If T preserves norms, then \langle T(v), T(w) \rangle = \frac{1}{4}(\|T(v+w)\|^2 - \|T(v-w)\|^2) = \frac{1}{4}(\|v+w\|^2 - \|v-w\|^2) = \langle v, w \rangle. The complex case is similar.
\implies (iii): If \mathcal{B} = \{e_1, \ldots, e_n\} is orthonormal and A = [T]_{\mathcal{B}}, then the (i,j)-entry of A^* A is (A^* A)_{ij} = \langle Ae_j, Ae_i \rangle = \langle T(e_j), T(e_i) \rangle = \langle e_j, e_i \rangle = \delta_{ij}. Thus A^* A = I.
\implies (iv): If A = [T]_{\mathcal{B}} is orthogonal and \mathcal{B} = \{e_1, \ldots, e_n\} is orthonormal, then T(e_i) has coordinates given by the i-th column of A. Since A^* A = I, these columns are orthonormal, so \{T(e_1), \ldots, T(e_n)\} is orthonormal.
\implies (i): Choose an orthonormal basis \mathcal{B}. By (iv), T(\mathcal{B}) is orthonormal. Any v, w \in \mathcal{V} expand as v = \sum c_i e_i and w = \sum d_i e_i. Then \langle T(v), T(w) \rangle = \left\langle \sum c_i T(e_i), \sum d_j T(e_j) \right\rangle = \sum_{i,j} c_i \overline{d_j} \langle T(e_i), T(e_j) \rangle = \sum_i c_i \overline{d_i} = \langle v, w \rangle. \quad \square
This theorem characterizes isometries: linear transformations preserving inner products are precisely those represented by orthogonal (or unitary) matrices in orthonormal coordinates.
11.8.2 Change of Orthonormal Bases
When changing between two orthonormal bases, the change-of-basis matrix is orthogonal (or unitary).
Theorem 11.18 Let \mathcal{B} and \mathcal{C} be orthonormal bases of a finite-dimensional inner product space \mathcal{V}. The change-of-basis matrix P from \mathcal{B} to \mathcal{C} is orthogonal (or unitary).
Proof. Let \mathcal{B} = \{e_1, \ldots, e_n\} and \mathcal{C} = \{f_1, \ldots, f_n\}. The j-th column of P contains the coordinates of e_j in basis \mathcal{C}: e_j = \sum_{i=1}^n p_{ij} f_i. Since both bases are orthonormal, \delta_{kj} = \langle e_k, e_j \rangle = \left\langle \sum_i p_{ik} f_i, \sum_\ell p_{\ell j} f_\ell \right\rangle = \sum_{i,\ell} p_{ik} \overline{p_{\ell j}} \langle f_i, f_\ell \rangle = \sum_i p_{ik} \overline{p_{ij}}. The (k,j)-entry of P^*P is (P^* P)_{kj} = \sum_i (P^*)_{ki}\,P_{ij} = \sum_i \overline{p_{ik}}\, p_{ij}. This is the complex conjugate of \sum_i p_{ik}\overline{p_{ij}}. Since \delta_{kj} \in \{0,1\} \subset \mathbb{R}, conjugating gives (P^*P)_{kj} = \delta_{kj} as well. Thus P^*P = I, so P is unitary (or orthogonal in the real case). \square
This result shows that orthonormal bases are related by isometries. The geometry encoded by one orthonormal basis is the same as that encoded by any other—they differ only by a rigid motion.
11.9 Least Squares Approximation
Consider the overdetermined system Ax = b where A \in M_{m \times n}(\mathbb{R}) with m > n. Typically no exact solution exists when m > n—we have more equations than unknowns. Instead, we seek x minimizing the residual \|Ax - b\|.
Definition 11.5 (Least squares solution) A vector \hat{x} \in \mathbb{R}^n is a least squares solution to Ax = b if \|A\hat{x} - b\| \le \|Ax - b\| for all x \in \mathbb{R}^n.
Geometrically, \hat{x} makes A\hat{x} the closest vector in \operatorname{Col}(A) to b. By Theorem 11.12, this is the orthogonal projection of b onto \operatorname{Col}(A).
Theorem 11.19 \hat{x} is a least squares solution to Ax = b if and only if \hat{x} satisfies the normal equations A^T A \hat{x} = A^T b.
Proof. Let \mathcal{W} = \operatorname{Col}(A) = \{Ax : x \in \mathbb{R}^n\}. The least squares solution \hat{x} satisfies A\hat{x} = P_{\mathcal{W}}(b), so b - A\hat{x} \in \mathcal{W}^\perp by Theorem 11.8.
Since \mathcal{W}^\perp is orthogonal to every vector in \mathcal{W}, and the columns of A span \mathcal{W}, we have \langle b - A\hat{x}, Ay \rangle = 0 for all y \in \mathbb{R}^n. Writing Ay = \sum y_i a_i where a_i are columns of A, linearity gives \langle b - A\hat{x}, a_i \rangle = 0 for all i. In matrix form, A^T (b - A\hat{x}) = 0, which rearranges to A^T A \hat{x} = A^T b. \square
When A has linearly independent columns, A^T A is invertible (its kernel is trivial), so the normal equations have the unique solution \hat{x} = (A^T A)^{-1} A^T b.
The matrix (A^T A)^{-1} A^T is the pseudoinverse of A, denoted A^\dagger in the literature. It provides the best approximate inverse when A is not square.
11.9.1 QR Approach to Least Squares
Computing (A^T A)^{-1} is numerically unstable. The QR decomposition provides a better method.
If A = QR with Q having orthonormal columns, then A^T A = R^T Q^T Q R = R^T R (since Q^T Q = I_n for orthonormal columns). The normal equations become R^T R \hat{x} = R^T Q^T b, which simplifies to R \hat{x} = Q^T b (multiply both sides by (R^T)^{-1}). Since R is upper triangular, back-substitution solves this system efficiently and stably.
Algorithm:
Compute A = QR via Gram-Schmidt.
Compute c = Q^T b.
Solve R \hat{x} = c by back-substitution.
This avoids forming A^T A and inverting it, eliminating sources of numerical error.
11.9.2 Application: Linear Regression
In statistics, linear regression fits a line (or hyperplane) to data points (x_i, y_i) for i = 1, \ldots, m. The model is y \approx \beta_0 + \beta_1 x. Writing A = \begin{pmatrix} 1 & x_1 \\ \vdots & \vdots \\ 1 & x_m \end{pmatrix}, x = \begin{pmatrix} \beta_0 \\ \beta_1 \end{pmatrix}, and b = \begin{pmatrix} y_1 \\ \vdots \\ y_m \end{pmatrix}, the least squares solution \hat{x} minimizes \sum_{i=1}^m (y_i - (\beta_0 + \beta_1 x_i))^2, the sum of squared residuals.
This extends to polynomial regression, multiple linear regression, and more complex models—all reducible to least squares via appropriate design matrices A.
11.10 Multiple Orthogonal Projections
When \mathcal{V} decomposes into several orthogonal subspaces, we obtain projections onto each summand.
Theorem 11.20 Let \mathcal{V} = \mathcal{W}_1 \oplus \cdots \oplus \mathcal{W}_k where the \mathcal{W}_i are pairwise orthogonal (i.e., \mathcal{W}_i \perp \mathcal{W}_j for i \neq j). Then every v \in \mathcal{V} decomposes uniquely as v = w_1 + \cdots + w_k with w_i \in \mathcal{W}_i, and w_i = P_{\mathcal{W}_i}(v).
Proof. The decomposition follows from \mathcal{V} = \bigoplus \mathcal{W}_i. To show w_i = P_{\mathcal{W}_i}(v), note that v - w_i = \sum_{j \neq i} w_j \in \bigoplus_{j \neq i} \mathcal{W}_j. Since \mathcal{W}_i \perp \mathcal{W}_j for j \neq i, we have v - w_i \perp \mathcal{W}_i, so by uniqueness of the orthogonal projection, w_i = P_{\mathcal{W}_i}(v). \square
Theorem 11.21 If \mathcal{V} = \mathcal{W}_1 \oplus \cdots \oplus \mathcal{W}_k with pairwise orthogonal subspaces, then P_{\mathcal{W}_1} + \cdots + P_{\mathcal{W}_k} = I.
Proof. For any v \in \mathcal{V}, write v = w_1 + \cdots + w_k with w_i \in \mathcal{W}_i. Then (P_{\mathcal{W}_1} + \cdots + P_{\mathcal{W}_k})(v) = P_{\mathcal{W}_1}(v) + \cdots + P_{\mathcal{W}_k}(v) = w_1 + \cdots + w_k = v. \quad \square
This identity states that projecting onto each subspace and summing reconstructs the original vector. It is the geometric manifestation of the direct sum decomposition.
Corollary 11.4 If \mathcal{W}_1 \perp \mathcal{W}_2, then P_{\mathcal{W}_1} P_{\mathcal{W}_2} = 0.
Proof. For any v \in \mathcal{V}, P_{\mathcal{W}_2}(v) \in \mathcal{W}_2. Since \mathcal{W}_1 \perp \mathcal{W}_2, we have P_{\mathcal{W}_2}(v) \in \mathcal{W}_1^\perp, so P_{\mathcal{W}_1}(P_{\mathcal{W}_2}(v)) = 0. \square
Orthogonal projections onto orthogonal subspaces commute and satisfy P_i P_j = 0 for i \neq j. This algebraic structure reflects the geometric decomposition.
11.11 Parseval’s Theorem and Fourier Series
In infinite-dimensional inner product spaces, orthonormal bases may be infinite. A fundamental question: does Parseval’s identity extend to infinite sums? To answer this rigorously, we first define the appropriate setting.
Definition 11.6 (Hilbert space) An inner product space \mathcal{V} is a Hilbert space if it is complete with respect to the metric d(u, v) = \|u - v\| induced by the norm \|v\| = \sqrt{\langle v, v \rangle}. That is, every Cauchy sequence in \mathcal{V} converges to an element of \mathcal{V} (see also Definition 10.5).
Completeness is the key property distinguishing Hilbert spaces from general inner product spaces. It ensures that limits of convergent sequences remain in the space, allowing us to work with infinite series.
Definition 11.7 (Orthonormal sequence) A sequence (e_n)_{n=1}^\infty in an inner product space \mathcal{V} is orthonormal if \langle e_m, e_n \rangle = \delta_{mn} for all m, n.
For v \in \mathcal{V}, the Fourier coefficients with respect to (e_n) are c_n = \langle v, e_n \rangle. If the series \sum_{n=1}^\infty c_n e_n converges, does it equal v? Does Parseval’s identity \|v\|^2 = \sum |c_n|^2 hold?
Theorem 11.22 (Bessel’s inequality) Let (e_n) be an orthonormal sequence in an inner product space \mathcal{V}. For any v \in \mathcal{V}, \sum_{n=1}^\infty |\langle v, e_n \rangle|^2 \le \|v\|^2.
Proof. For any finite N, let v_N = \sum_{n=1}^N \langle v, e_n \rangle e_n. This is the projection of v onto \operatorname{span}\{e_1, \ldots, e_N\}. By Theorem 11.4, \|v_N\|^2 = \sum_{n=1}^N |\langle v, e_n \rangle|^2. By Theorem 11.12, \|v_N\| \le \|v\|, so \sum_{n=1}^N |\langle v, e_n \rangle|^2 \le \|v\|^2. Taking N \to \infty gives Bessel’s inequality. \square
When equality holds for all v, the sequence (e_n) is called complete or a Hilbert basis.
Theorem 11.23 (Parseval’s theorem) Let \mathcal{V} be a separable Hilbert space with orthonormal basis (e_n)_{n=1}^\infty. For any v \in \mathcal{V}, v = \sum_{n=1}^\infty \langle v, e_n \rangle e_n, \quad \|v\|^2 = \sum_{n=1}^\infty |\langle v, e_n \rangle|^2.
Proof. Let c_n = \langle v, e_n \rangle and define the partial sums s_N = \sum_{n=1}^N c_n e_n. We first show (s_N) is a Cauchy sequence.
For M > N, \begin{align*} \|s_M - s_N\|^2 &= \left\| \sum_{n=N+1}^M c_n e_n \right\|^2 \\ &= \sum_{n=N+1}^M |c_n|^2, \end{align*} using orthonormality of (e_n). By Bessel’s inequality (Theorem 11.22), \sum_{n=1}^\infty |c_n|^2 \le \|v\|^2 < \infty. Thus \sum |c_n|^2 converges, so its tail vanishes: for any \varepsilon > 0, there exists N_0 such that \sum_{n=N+1}^M |c_n|^2 < \varepsilon for all M > N \ge N_0. Hence \|s_M - s_N\| < \sqrt{\varepsilon} for M > N \ge N_0, proving (s_N) is Cauchy.
By completeness of \mathcal{V}, there exists w \in \mathcal{V} with s_N \to w. We claim w = v. For any m, \langle w, e_m \rangle = \lim_{N \to \infty} \langle s_N, e_m \rangle = \lim_{N \to \infty} \sum_{n=1}^N c_n \langle e_n, e_m \rangle = c_m, by continuity of the inner product. Thus \langle v - w, e_m \rangle = c_m - c_m = 0 for all m.
Since (e_n) is a basis, for any u \in \mathcal{V} orthogonal to all e_n, we have u = 0. (If not, there exists u \neq 0 with \langle u, e_n \rangle = 0 for all n. But (e_n) being a basis means the closed span of \{e_n\} equals \mathcal{V}, contradicting u \perp \operatorname{span}\{e_n\} and u \neq 0.) Thus v - w = 0, so v = w = \sum_{n=1}^\infty c_n e_n.
For the norm equality, by continuity of the norm, \|v\|^2 = \lim_{N \to \infty} \|s_N\|^2 = \lim_{N \to \infty} \sum_{n=1}^N |c_n|^2 = \sum_{n=1}^\infty |c_n|^2. This completes the proof. \square
Parseval’s theorem shows that Hilbert space structure—orthonormal bases and completeness—enables infinite expansions with norm preservation, generalizing finite-dimensional decompositions.
11.11.1 Example: Fourier Series
Consider \mathcal{V} = L^2([0, 2\pi]), the space of square-integrable functions f : [0, 2\pi] \to \mathbb{C} with inner product \langle f, g \rangle = \int_0^{2\pi} f(x) \overline{g(x)} \, dx.
The functions e_n(x) = e^{inx} / \sqrt{2\pi} for n \in \mathbb{Z} form an orthonormal basis. The Fourier coefficients are \hat{f}(n) = \langle f, e_n \rangle = \frac{1}{\sqrt{2\pi}} \int_0^{2\pi} f(x) e^{-inx} \, dx.
Parseval’s theorem states f(x) = \sum_{n=-\infty}^\infty \hat{f}(n) e^{inx} / \sqrt{2\pi}, \quad \int_0^{2\pi} |f(x)|^2 \, dx = 2\pi \sum_{n=-\infty}^\infty |\hat{f}(n)|^2.
The first equation is the Fourier series expansion: every function decomposes into a sum of complex exponentials. The second is Parseval’s identity for Fourier series: the total energy \int |f|^2 equals the sum of energies in each frequency component.
This result underpins signal processing, quantum mechanics, and harmonic analysis. It shows that orthonormal expansions preserve energy and that functions in L^2 spaces admit complete spectral decompositions.
11.12 Closing Remarks
The central thread of this chapter is the orthogonal decomposition \mathcal{V} = \mathcal{W} \oplus \mathcal{W}^\perp: every vector splits uniquely into a component inside a subspace and one perpendicular to it, and the component inside is the closest point in \mathcal{W}. Gram-Schmidt turns this into an algorithm—any basis can be orthonormalized, and the process records itself as the QR factorization A = QR, which gives a numerically stable route to least squares via R\hat{x} = Q^T b.
Parseval’s identity \|v\|^2 = \sum |\langle v, e_n \rangle|^2 shows that an orthonormal basis preserves norms and encodes all information about v in its Fourier coefficients—a finite-dimensional statement that carries over to Hilbert spaces and underlies classical Fourier analysis. Chapter 12 puts these tools to work on the spectral theorem.