9 Invariant Subspaces and Eigenvalues
9.1 The Structure Problem for Operators
A linear map T : \mathcal{V} \to \mathcal{W} between distinct spaces transforms geometric objects from one ambient context to another. When domain and codomain coincide—when T : \mathcal{V} \to \mathcal{V} is an operator—the transformation acts on the space itself. The central question becomes: what is the simplest coordinate system in which T can be expressed?
Consider a projection P : \mathbb{R}^3 \to \mathbb{R}^3 onto a plane \mathcal{W} through the origin. The plane is mapped into itself; the orthogonal complement is collapsed to zero. In coordinates adapted to this decomposition \mathbb{R}^3 = \mathcal{W}_1 \oplus \mathcal{W}_2, the matrix is block-diagonal: P acts as identity on \mathcal{W}_1 and as zero on \mathcal{W}_2. The geometric decomposition induces an algebraic simplification.
More generally, if a subspace \mathcal{W} \subseteq \mathcal{V} is invariant under T—if T(\mathcal{W}) \subseteq \mathcal{W}—then T restricts to an operator on \mathcal{W}, and choosing bases adapted to invariant subspaces yields block-structured matrices. When \mathcal{V} decomposes as a direct sum of invariant subspaces, T decomposes into independent operators on each summand.
The ultimate simplification occurs when \mathcal{V} admits a decomposition into one-dimensional invariant subspaces. On a line \operatorname{span}(v), any operator acts as scalar multiplication. If \mathcal{V} decomposes into such lines, T becomes diagonal—the simplest possible form.
This chapter develops the theory systematically. We begin with direct sums, characterize invariant subspaces and their interaction with matrix representations, identify one-dimensional invariant subspaces with eigenvectors, and determine when operators admit diagonalization. The characteristic polynomial emerges as the computational tool detecting eigenvalues, and the spectral structure—the collection of eigenvalues and eigenspaces—determines the extent to which T can be simplified.
9.2 Direct Sum Decompositions
We established in Chapter 2 that vector spaces decompose into independent summands. The construction generalizes naturally beyond pairs.
Definition 9.1 (Direct sum) Subspaces \mathcal{W}_1, \ldots, \mathcal{W}_k \subseteq \mathcal{V} form a direct sum if every v \in \mathcal{V} admits a unique decomposition v = w_1 + \cdots + w_k with w_i \in \mathcal{W}_i. We write \mathcal{V} = \mathcal{W}_1 \oplus \cdots \oplus \mathcal{W}_k = \bigoplus_{i=1}^k \mathcal{W}_i.
Theorem 9.1 The following are equivalent:
\mathcal{V} = \bigoplus_{i=1}^k \mathcal{W}_i
\mathcal{V} = \sum_{i=1}^k \mathcal{W}_i and the only representation of 0 as \sum w_i with w_i \in \mathcal{W}_i has all w_i = 0
\mathcal{V} = \sum_{i=1}^k \mathcal{W}_i and for each j, \mathcal{W}_j \cap \left(\sum_{i \neq j} \mathcal{W}_i\right) = \{0\}
Proof. (i) \iff (ii) is immediate from the definition: uniqueness of the decomposition of every vector is equivalent to uniqueness of the decomposition of zero.
For (ii) \implies (iii): suppose w_j \in \mathcal{W}_j \cap (\sum_{i \neq j} \mathcal{W}_i). Write w_j = \sum_{i \neq j} w_i with w_i \in \mathcal{W}_i. Rearranging, w_j + \sum_{i \neq j}(-w_i) = 0. By (ii) all terms vanish, so w_j = 0.
For (iii) \implies (ii): suppose \sum_{i=1}^k w_i = 0 with w_i \in \mathcal{W}_i. Fix any j; then w_j = -\sum_{i \neq j} w_i \in \sum_{i \neq j} \mathcal{W}_i. So w_j \in \mathcal{W}_j \cap (\sum_{i \neq j} \mathcal{W}_i) = \{0\}. Since j was arbitrary, all w_i = 0. \square
Corollary 9.1 If \mathcal{V} = \bigoplus_{i=1}^k \mathcal{W}_i and \dim \mathcal{V} < \infty, then \dim \mathcal{V} = \sum_{i=1}^k \dim \mathcal{W}_i.
Proof. Choose a basis \mathcal{B}_i for each \mathcal{W}_i and let \mathcal{B} = \bigcup_i \mathcal{B}_i. Spanning is immediate since every v = \sum w_i and each w_i lies in the span of \mathcal{B}_i. For independence, suppose \sum_{i,\ell} c_{i\ell} b_{i\ell} = 0 where b_{i\ell} \in \mathcal{B}_i. Grouping by summand, write u_i = \sum_\ell c_{i\ell} b_{i\ell} \in \mathcal{W}_i; then \sum_i u_i = 0. By Theorem 9.1 (ii), each u_i = 0, and by independence of \mathcal{B}_i, each c_{i\ell} = 0. \square
The direct sum provides coordinates adapted to the decomposition: every vector v is uniquely determined by its components (w_1, \ldots, w_k) with w_i \in \mathcal{W}_i. Understanding \mathcal{V} reduces to understanding each \mathcal{W}_i independently.
From Chapter 3, the kernel-image decomposition exemplifies this structure: for T : \mathcal{V} \to \mathcal{W} with \mathcal{V} finite-dimensional, there exists \mathcal{U} \subseteq \mathcal{V} with \mathcal{V} = \ker(T) \oplus \mathcal{U} and T|_{\mathcal{U}} : \mathcal{U} \to \operatorname{im}(T) an isomorphism. The decomposition separates what T annihilates from what it preserves.
9.3 Invariant Subspaces
Let T : \mathcal{V} \to \mathcal{V} be a linear operator.
Definition 9.2 (Invariant subspace) A subspace \mathcal{W} \subseteq \mathcal{V} is T-invariant if T(\mathcal{W}) \subseteq \mathcal{W}.
Equivalently, \mathcal{W} is T-invariant if T restricts to an operator T|_{\mathcal{W}} : \mathcal{W} \to \mathcal{W}. The subspace forms a closed subsystem under iteration of T.
The trivial examples \{0\} and \mathcal{V} are always T-invariant. Nontrivial invariant subspaces reveal finer structure. Both \ker(T) and \operatorname{im}(T) are T-invariant: if T(v) = 0 then T(T(v)) = T(0) = 0, and if w = T(v) then T(w) = T^2(v) \in \operatorname{im}(T).
Theorem 9.2 Let \mathcal{W} \subseteq \mathcal{V} be T-invariant with \dim \mathcal{W} = k. Choose a basis \mathcal{B} of \mathcal{V} whose first k vectors span \mathcal{W}. Then [T]_{\mathcal{B}} = \begin{pmatrix} A & B \\ 0 & D \end{pmatrix} where A \in M_{k \times k}(\mathbb{F}) represents T|_{\mathcal{W}}.
Proof. Let \mathcal{B} = \{w_1, \ldots, w_k, v_{k+1}, \ldots, v_n\} where \{w_1, \ldots, w_k\} is a basis of \mathcal{W}. For j \leq k, T(w_j) \in \mathcal{W} = \operatorname{span}(w_1, \ldots, w_k), so the j-th column of [T]_{\mathcal{B}} has zeros in positions k+1 through n. This gives the block structure; A records the action of T on \mathcal{W} in the basis \{w_1, \ldots, w_k\}, and B records how T maps the v_j into \mathcal{W}. \square
The block-triangular form reflects that T cannot map \mathcal{W} outside itself. By Theorem 8.9 from Chapter 7, \det([T]_{\mathcal{B}}) = \det(A)\det(D)—the determinant factors according to the invariant subspace decomposition.
When both \mathcal{W} and a complement are invariant, the structure simplifies further.
Definition 9.3 (Reducing pair) Subspaces \mathcal{W}_1, \mathcal{W}_2 \subseteq \mathcal{V} form a reducing pair for T if \mathcal{V} = \mathcal{W}_1 \oplus \mathcal{W}_2 and both are T-invariant.
Theorem 9.3 If \mathcal{V} = \mathcal{W}_1 \oplus \mathcal{W}_2 with both \mathcal{W}_i T-invariant, then in a basis adapted to the decomposition, [T] = \begin{pmatrix} A & 0 \\ 0 & D \end{pmatrix} where A and D represent T|_{\mathcal{W}_1} and T|_{\mathcal{W}_2} respectively.
Proof. Apply Theorem 9.2 to \mathcal{W}_1, obtaining the upper block-triangular structure with A in the top-left block. It remains to show the upper-right block B vanishes. For each basis vector v \in \mathcal{W}_2, T(v) \in \mathcal{W}_2 by invariance of \mathcal{W}_2. But \mathcal{W}_1 \cap \mathcal{W}_2 = \{0\}, so T(v) has no component in \mathcal{W}_1. Thus the upper-right block is zero, and D records the action of T|_{\mathcal{W}_2}. \square
The operator decomposes: T acts on \mathcal{W}_1 and \mathcal{W}_2 independently. Powers and polynomials respect this decomposition: if [T] = \operatorname{diag}(A, D), then [T^k] = \operatorname{diag}(A^k, D^k) and [p(T)] = \operatorname{diag}(p(A), p(D)) for any polynomial p.
More generally, if \mathcal{V} = \bigoplus_{i=1}^k \mathcal{W}_i with all \mathcal{W}_i invariant, then [T] is block-diagonal with blocks A_1, \ldots, A_k representing T|_{\mathcal{W}_i}. Understanding T reduces to understanding each restriction T|_{\mathcal{W}_i} independently.
While block-diagonal structure simplifies analysis, the ultimate reduction occurs when each block is 1 \times 1—that is, when every invariant summand is one-dimensional. On a line \operatorname{span}(v), any linear operator acts by stretching or shrinking: there is only one degree of freedom, so T(v) must be a scalar multiple of v. If we can decompose \mathcal{V} into one-dimensional invariant subspaces, choosing a basis vector from each yields a coordinate system where T is diagonal—each coordinate is scaled independently.
This motivates our focus on one-dimensional invariant subspaces. Their existence and multiplicity determine whether an operator can be diagonalized.
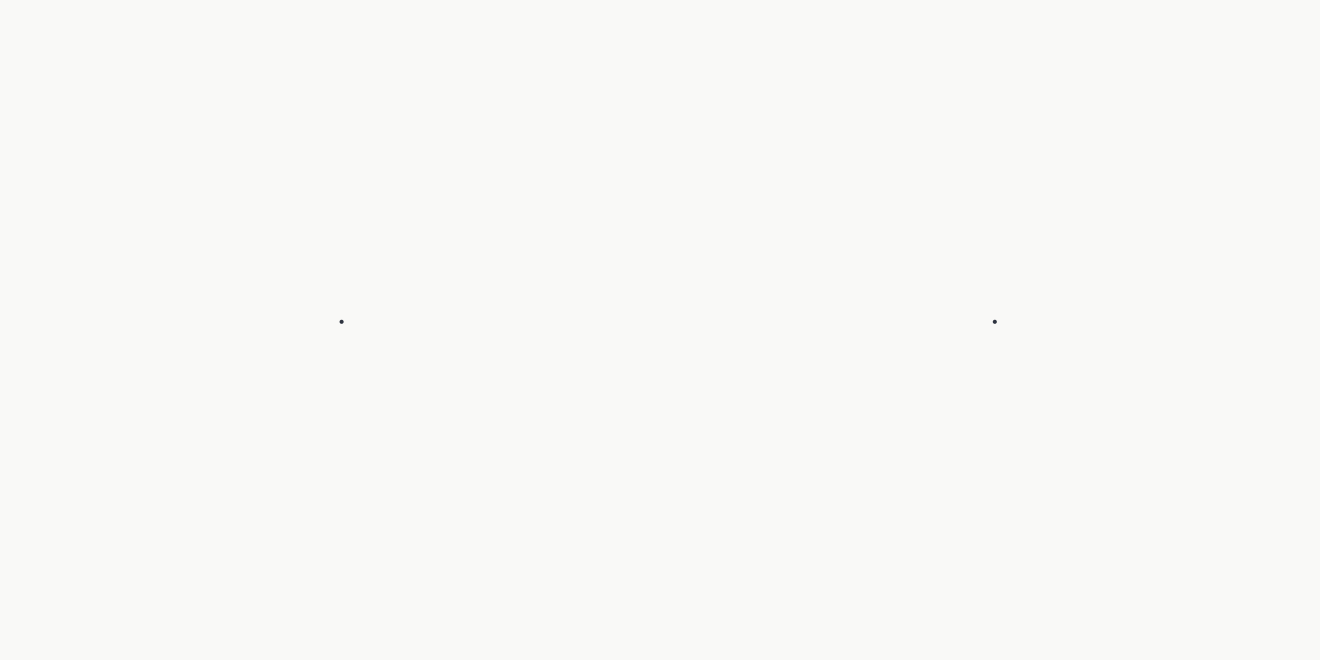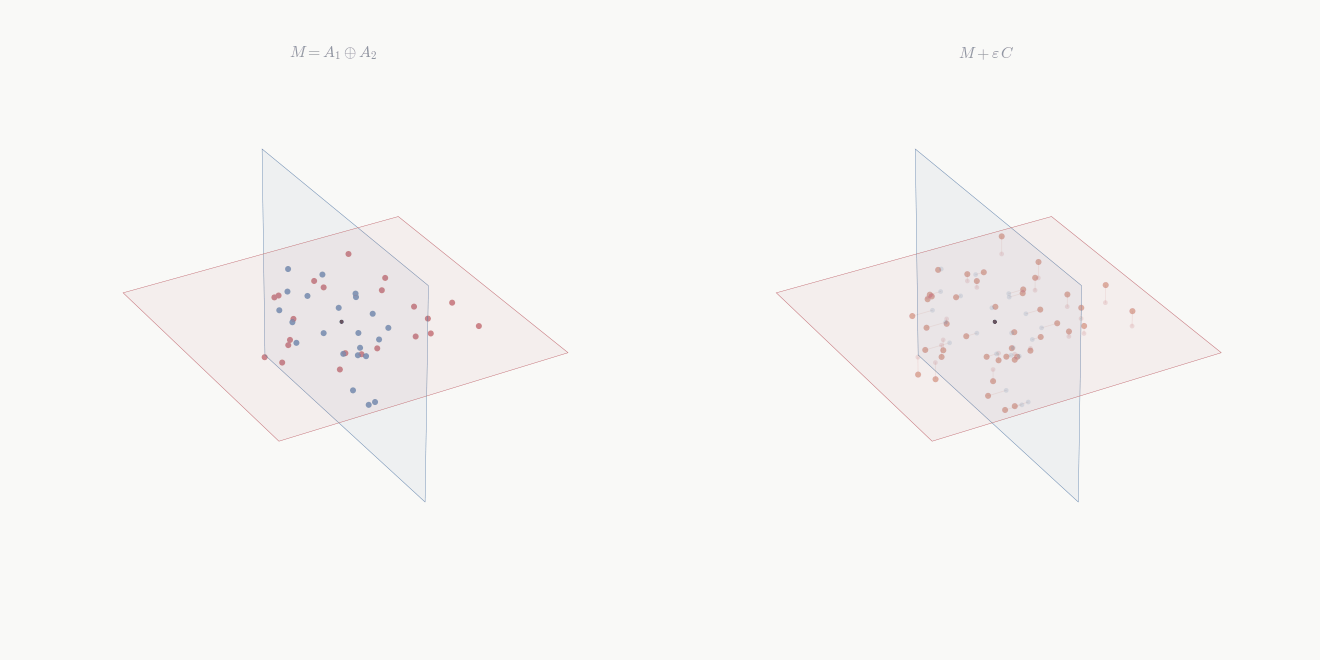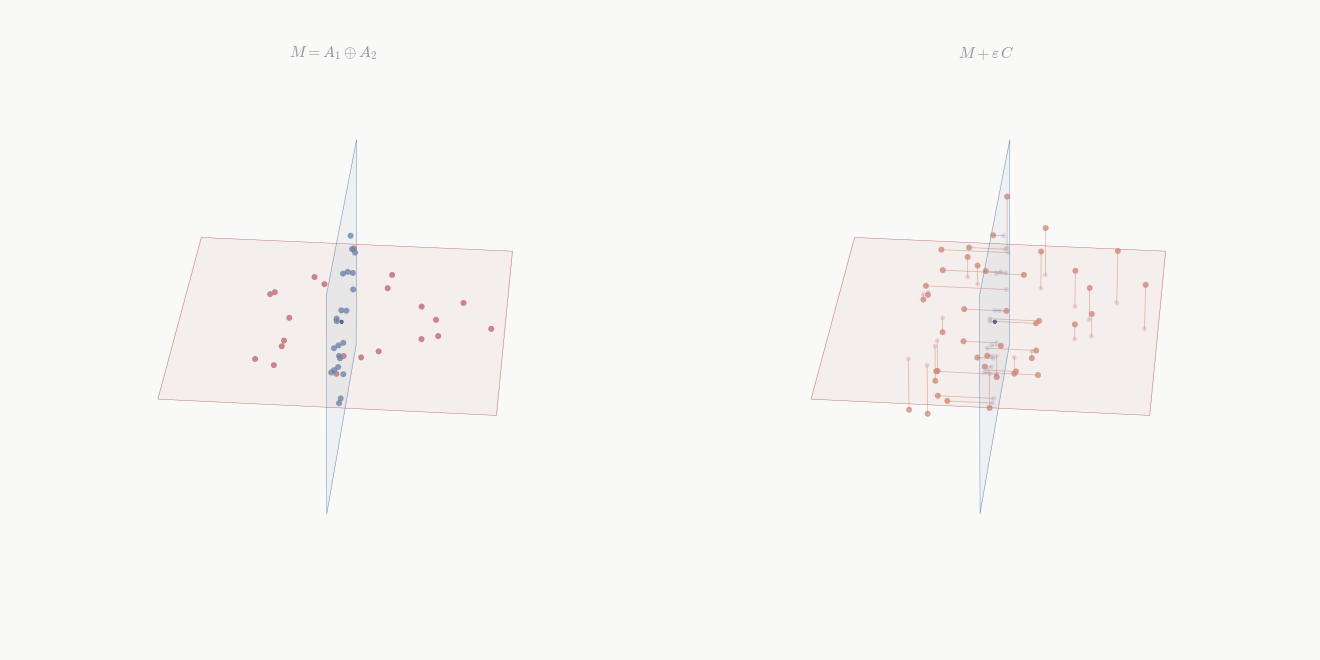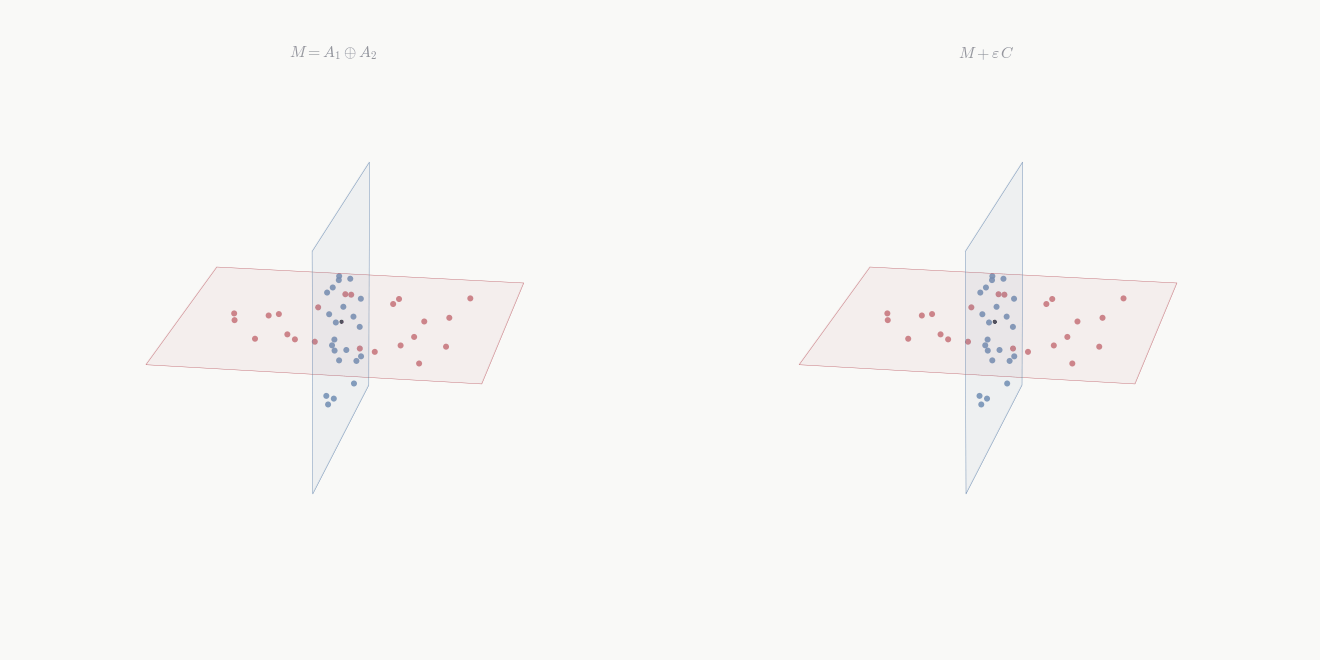
9.4 One-Dimensional Invariant Subspaces
The simplest nontrivial invariant subspaces are lines through the origin.
Theorem 9.4 A one-dimensional subspace \operatorname{span}(v) with v \neq 0 is T-invariant if and only if T(v) = \lambda v for some \lambda \in \mathbb{F}.
Proof. If \operatorname{span}(v) is invariant, then T(v) \in \operatorname{span}(v), so T(v) = \lambda v for some \lambda. Conversely, if T(v) = \lambda v, then for any cv \in \operatorname{span}(v), T(cv) = cT(v) = c\lambda v \in \operatorname{span}(v). \square
On a one-dimensional invariant subspace, any operator acts as scalar multiplication. This is the simplest possible action.
Definition 9.4 (Eigenvector and eigenvalue) A nonzero vector v \in \mathcal{V} is an eigenvector of T with eigenvalue \lambda \in \mathbb{F} if T(v) = \lambda v.
The set of all eigenvectors with eigenvalue \lambda, together with the zero vector, forms the eigenspace E_\lambda = \ker(T - \lambda I).
By Theorem 4.4 from Chapter 3, E_\lambda is a subspace. Note that \lambda is an eigenvalue if and only if E_\lambda \neq \{0\}, equivalently if T - \lambda I is not injective.
Theorem 9.5 Each eigenspace E_\lambda is T-invariant.
Proof. Let v \in E_\lambda, so T(v) = \lambda v. We must show T(v) \in E_\lambda, i.e., that T(T(v)) = \lambda \cdot T(v). By linearity, T(T(v)) = T(\lambda v) = \lambda T(v). Thus T(v) \in E_\lambda. \square
In fact, T acts on E_\lambda as the scalar operator \lambda I: the restriction T|_{E_\lambda} is multiplication by \lambda.
Theorem 9.6 Let v_1, \ldots, v_k be eigenvectors with distinct eigenvalues \lambda_1, \ldots, \lambda_k. Then \{v_1, \ldots, v_k\} is linearly independent.
Proof. By induction on k. The base case k=1 is immediate since eigenvectors are nonzero. Suppose \sum_{i=1}^k c_i v_i = 0. Applying T gives \sum_{i=1}^k c_i \lambda_i v_i = 0. Subtracting \lambda_k times the original relation: \sum_{i=1}^{k-1} c_i(\lambda_i - \lambda_k)v_i = 0. By the induction hypothesis, c_i(\lambda_i - \lambda_k) = 0 for i = 1, \ldots, k-1. Since \lambda_i \neq \lambda_k, we have c_i = 0 for i < k. Substituting back gives c_k v_k = 0, hence c_k = 0. \square
Corollary 9.2 If \lambda_1, \ldots, \lambda_k are distinct eigenvalues, then E_{\lambda_1} + \cdots + E_{\lambda_k} = E_{\lambda_1} \oplus \cdots \oplus E_{\lambda_k}.
Proof. By Theorem 9.1 (ii), we check that the only representation of 0 as v_1 + \cdots + v_k with v_i \in E_{\lambda_i} has all v_i = 0. If \sum_{i=1}^k v_i = 0, choose a basis for each eigenspace and expand each v_i as a linear combination. The resulting relation expresses zero as a linear combination of eigenvectors with distinct eigenvalues, so all coefficients vanish by Theorem 9.6, giving v_i = 0 for all i. \square
Eigenspaces corresponding to different eigenvalues are maximally independent: they intersect only at the origin. If \mathcal{V} = \bigoplus_i E_{\lambda_i}, then in a basis of eigenvectors, T is diagonal with eigenvalues along the diagonal.
9.4.1 Example: Finding Eigenvectors
Consider T : \mathbb{R}^3 \to \mathbb{R}^3 with matrix A = \begin{pmatrix} 4 & 0 & 1 \\ 2 & 3 & 2 \\ 1 & 0 & 4 \end{pmatrix} relative to the standard basis. We seek one-dimensional invariant subspaces—equivalently, vectors v such that Av = \lambda v for some scalar \lambda.
The condition Av = \lambda v is equivalent to (A - \lambda I)v = 0, which has nonzero solutions precisely when A - \lambda I is not invertible. The characteristic polynomial (developed in the next section) reveals the eigenvalues to be \lambda = 3 and \lambda = 5.
For \lambda = 3: A - 3I = \begin{pmatrix} 1 & 0 & 1 \\ 2 & 0 & 2 \\ 1 & 0 & 1 \end{pmatrix}. The system (A - 3I)v = 0 row-reduces to v_1 + v_3 = 0 with v_2 free. Setting v_2 = 1 and v_3 = t yields eigenvectors \begin{pmatrix} -t \\ 1 \\ t \end{pmatrix}. Thus E_3 = \operatorname{span}\left\{\begin{pmatrix} -1 \\ 0 \\ 1 \end{pmatrix}, \begin{pmatrix} 0 \\ 1 \\ 0 \end{pmatrix}\right\} has dimension 2.
For \lambda = 5: A - 5I = \begin{pmatrix} -1 & 0 & 1 \\ 2 & -2 & 2 \\ 1 & 0 & -1 \end{pmatrix}. Row reduction gives v_1 = v_3 and v_2 = 2v_3. Thus E_5 = \operatorname{span}\left\{\begin{pmatrix} 1 \\ 2 \\ 1 \end{pmatrix}\right\} has dimension 1.
Since \dim E_3 + \dim E_5 = 3 = \dim \mathbb{R}^3, the operator is diagonalizable. In the basis \mathcal{B} = \left\{\begin{pmatrix} -1 \\ 0 \\ 1 \end{pmatrix}, \begin{pmatrix} 0 \\ 1 \\ 0 \end{pmatrix}, \begin{pmatrix} 1 \\ 2 \\ 1 \end{pmatrix}\right\}, the matrix of T is \begin{pmatrix} 3 & 0 & 0 \\ 0 & 3 & 0 \\ 0 & 0 & 5 \end{pmatrix}. The decomposition \mathbb{R}^3 = E_3 \oplus E_5 renders T transparent: it stretches by factor 3 along the plane E_3 and by factor 5 along the line E_5.
9.5 The Characteristic Polynomial
To determine eigenvalues systematically, observe that \lambda is an eigenvalue if and only if E_\lambda = \ker(T - \lambda I) \neq \{0\}, equivalently if T - \lambda I is not invertible. For finite-dimensional spaces, non-invertibility is detected by the determinant vanishing.
Definition 9.5 (Characteristic polynomial) For T : \mathcal{V} \to \mathcal{V} with \dim \mathcal{V} = n < \infty, the characteristic polynomial is \chi_T(\lambda) = \det(T - \lambda I).
This is a polynomial of degree n in \lambda. To verify the definition is basis-independent, note that if A = [T]_{\mathcal{B}} and B = [T]_{\mathcal{C}}, then B = P^{-1}AP for some invertible P by Theorem 6.3 from Chapter 5. Thus \det(B - \lambda I) = \det(P^{-1}(A - \lambda I)P) = \det(P^{-1})\det(A - \lambda I)\det(P) = \det(A - \lambda I) by multiplicativity of the determinant. The characteristic polynomial depends only on T, not on coordinates.
9.5.1 Example: Computing the Characteristic Polynomial
For the matrix from our earlier example, A = \begin{pmatrix} 4 & 0 & 1 \\ 2 & 3 & 2 \\ 1 & 0 & 4 \end{pmatrix}, expanding along the second column (which has two zeros): \chi_A(\lambda) = (3-\lambda) \det\begin{pmatrix} 4-\lambda & 1 \\ 1 & 4-\lambda \end{pmatrix} = (3-\lambda)\bigl[(4-\lambda)^2 - 1\bigr]. Since (4-\lambda)^2 - 1 = (\lambda-3)(\lambda-5), we obtain \chi_A(\lambda) = -(λ-3)^2(\lambda-5). The roots are \lambda = 3 (algebraic multiplicity 2) and \lambda = 5 (algebraic multiplicity 1), confirming our earlier computation.
Theorem 9.7 \lambda \in \mathbb{F} is an eigenvalue of T if and only if \chi_T(\lambda) = 0.
Proof. \lambda is an eigenvalue \iff T - \lambda I is not invertible \iff \det(T - \lambda I) = 0 by Theorem 7.11 from Chapter 6. \square
Over an algebraically closed field such as \mathbb{C}, every polynomial of degree n has exactly n roots counting multiplicity, so every operator on a finite-dimensional complex vector space has eigenvalues. Over \mathbb{R}, polynomials may have fewer than n real roots—a rotation in \mathbb{R}^2 by angle \theta \notin \{0, \pi\} has no real eigenvalues—so real operators may lack real eigenvalues.
Definition 9.6 (Algebraic and geometric multiplicity) The algebraic multiplicity of eigenvalue \lambda is its multiplicity as a root of \chi_T.
The geometric multiplicity of \lambda is \dim E_\lambda = \dim \ker(T - \lambda I).
Theorem 9.8 For any eigenvalue \lambda, 1 \leq \operatorname{geom. mult.}(\lambda) \leq \operatorname{alg. mult.}(\lambda).
The lower bound is immediate: \lambda being an eigenvalue means E_\lambda \neq \{0\}, so \dim E_\lambda \geq 1. The upper bound is deferred to the Jordan canonical form discussion below, where it emerges naturally from the structure of generalized eigenspaces; its proof requires machinery beyond the present section.
9.6 Diagonalizability
An operator T : \mathcal{V} \to \mathcal{V} is diagonalizable if there exists a basis \mathcal{B} of \mathcal{V} consisting entirely of eigenvectors, equivalently if [T]_{\mathcal{B}} is diagonal.
Theorem 9.9 The following are equivalent:
T is diagonalizable
\mathcal{V} = \bigoplus_{\lambda} E_\lambda where the sum ranges over all eigenvalues of T
\sum_{\lambda} \dim E_\lambda = \dim \mathcal{V} where the sum ranges over all eigenvalues
Proof. (i) \implies (ii): If \mathcal{B} is an eigenbasis, partition \mathcal{B} by eigenvalue: \mathcal{B} = \bigcup_{\lambda} \mathcal{B}_\lambda where \mathcal{B}_\lambda consists of eigenvectors with eigenvalue \lambda. Then \operatorname{span}(\mathcal{B}_\lambda) \subseteq E_\lambda, and since \mathcal{B} spans \mathcal{V}, we have \mathcal{V} = \sum_\lambda E_\lambda. The sum is direct by Corollary 9.2.
\implies (iii): Immediate from Corollary 9.1.
\implies (i): Choose a basis for each E_\lambda. The union has \sum \dim E_\lambda = \dim \mathcal{V} vectors. By Corollary 9.2 and Corollary 9.1, these bases concatenate to a basis of \mathcal{V}, and every vector in this basis is an eigenvector. \square
When T is diagonalizable, a basis of eigenvectors reduces T to its simplest form: in coordinates, [T]_{\mathcal{B}} = \operatorname{diag}(\lambda_1, \ldots, \lambda_n) where eigenvalues appear according to their geometric multiplicity. Powers simplify dramatically: [T^k]_{\mathcal{B}} = \operatorname{diag}(\lambda_1^k, \ldots, \lambda_n^k).
Not all operators are diagonalizable. The canonical example is T : \mathbb{R}^2 \to \mathbb{R}^2 with matrix \begin{pmatrix} 2 & 1 \\ 0 & 2 \end{pmatrix}. The characteristic polynomial is -(λ-2)^2, giving eigenvalue \lambda = 2 with algebraic multiplicity 2. The eigenspace is E_2 = \ker\begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} = \operatorname{span}\{e_1\}, which has dimension 1. Since geometric multiplicity 1 < algebraic multiplicity 2, the operator is not diagonalizable.
Theorem 9.10 If T has \dim \mathcal{V} distinct eigenvalues, then T is diagonalizable.
Proof. Let \lambda_1, \ldots, \lambda_n be n = \dim \mathcal{V} distinct eigenvalues with eigenvectors v_1, \ldots, v_n. By Theorem 9.6, these form a linearly independent set of size n = \dim \mathcal{V}, hence a basis. \square
This sufficient condition is not necessary: an operator can be diagonalizable with fewer than n distinct eigenvalues if eigenspaces have dimension greater than 1 (e.g., scalar operators T = cI have only one eigenvalue but are already diagonal).
9.7 Spectral Properties
The spectrum of T is the set of its eigenvalues. The determinant and trace encode spectral information.
Theorem 9.11 If \lambda_1, \ldots, \lambda_n are the eigenvalues of T counted with algebraic multiplicity, then \det(T) = \prod_{i=1}^n \lambda_i.
Proof. Over an algebraically closed field, the characteristic polynomial factors as \chi_T(\lambda) = \det(A - \lambda I) = (-1)^n(\lambda - \lambda_1) \cdots (\lambda - \lambda_n). Setting \lambda = 0 gives the constant term on both sides. The left side yields \det(A). The right side yields (-1)^n(-\lambda_1)\cdots(-\lambda_n) = \prod_{i=1}^n \lambda_i. \square
Theorem 9.12 If \lambda_1, \ldots, \lambda_n are the eigenvalues of T counted with algebraic multiplicity, then \operatorname{tr}(T) = \sum_{i=1}^n \lambda_i.
Proof. The characteristic polynomial factors as (-1)^n(\lambda - \lambda_1)\cdots(\lambda - \lambda_n). Expanding, the coefficient of \lambda^{n-1} is (-1)^{n-1}(\lambda_1 + \cdots + \lambda_n). On the other hand, \det(A - \lambda I) is computed by expanding the determinant: the only term contributing to \lambda^{n-1} arises from the product of diagonal entries (a_{11} - \lambda)(a_{22} - \lambda)\cdots(a_{nn} - \lambda), and the coefficient of \lambda^{n-1} in this product is (-1)^{n-1}(a_{11} + \cdots + a_{nn}) = (-1)^{n-1}\operatorname{tr}(A). Equating the two expressions for the coefficient of \lambda^{n-1} gives \operatorname{tr}(A) = \sum \lambda_i. \square
These identities reveal the geometric content of determinant and trace: the determinant measures the product of stretching factors along eigendirections, while the trace measures their sum. For diagonalizable operators this is immediate from the diagonal form; the theorems assert it holds universally, even for non-diagonalizable operators.
9.8 The Jordan Canonical Form
When an operator fails to diagonalize, the Jordan form provides the next-best decomposition.
Definition 9.7 (Jordan block) A Jordan block with eigenvalue \lambda and size k is the k \times k matrix J_k(\lambda) = \begin{pmatrix} \lambda & 1 & 0 & \cdots & 0 \\ 0 & \lambda & 1 & \cdots & 0 \\ \vdots & & \ddots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda & 1 \\ 0 & 0 & \cdots & 0 & \lambda \end{pmatrix}.
A Jordan block is nearly diagonal: the eigenvalue \lambda appears on the diagonal, with 1’s on the superdiagonal. For example, J_3(2) = \begin{pmatrix} 2 & 1 & 0 \\ 0 & 2 & 1 \\ 0 & 0 & 2 \end{pmatrix}.
Theorem 9.13 (Jordan canonical form) Let T : \mathcal{V} \to \mathcal{V} be a linear operator on a finite-dimensional complex vector space. There exists a basis \mathcal{B} such that [T]_{\mathcal{B}} is block-diagonal with Jordan blocks: [T]_{\mathcal{B}} = \begin{pmatrix} J_{k_1}(\lambda_1) & & \\ & \ddots & \\ & & J_{k_m}(\lambda_m) \end{pmatrix}. This form is unique up to reordering of blocks.
The proof requires developing the theory of generalized eigenvectors and nilpotent operators, which lies beyond our scope. The key insight: when geometric multiplicity falls short of algebraic multiplicity, we obtain Jordan blocks of size larger than 1—this is precisely what the upper bound in Theorem 9.8 is detecting. The geometric multiplicity of \lambda equals the number of Jordan blocks with eigenvalue \lambda, while the algebraic multiplicity equals the total size of those blocks.
Example. The operator with matrix A = \begin{pmatrix} 2 & 1 \\ 0 & 2 \end{pmatrix} has eigenvalue \lambda = 2 with algebraic multiplicity 2 but geometric multiplicity 1: only one eigenvector. The matrix is already in Jordan form J_2(2). For higher powers, writing J_2(2) = 2I + N where N = \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} is nilpotent with N^2 = 0: J_2(2)^n = (2I + N)^n = \sum_{j=0}^{1}\binom{n}{j} 2^{n-j} N^j = \begin{pmatrix} 2^n & n \cdot 2^{n-1} \\ 0 & 2^n \end{pmatrix}. The off-diagonal entry grows as n \cdot 2^{n-1}, introducing polynomial factors alongside the exponential growth.
Theorem 9.14 For a linear operator T on a finite-dimensional complex vector space, T^n \to 0 as n \to \infty if and only if \rho(T) < 1, where \rho(T) = \max\{|\lambda| : \lambda \text{ eigenvalue of } T\} is the spectral radius.
Proof. By the Jordan canonical form, it suffices to check each Jordan block J_k(\lambda). Write J_k(\lambda) = \lambda I + N where N is strictly upper-triangular and nilpotent (N^k = 0). The binomial theorem gives J_k(\lambda)^n = (\lambda I + N)^n = \sum_{j=0}^{k-1} \binom{n}{j} \lambda^{n-j} N^j.
If |\lambda| < 1, each term satisfies \left|\binom{n}{j}\lambda^{n-j}\right| \leq \binom{n}{j}|\lambda|^{n-j}. Since \binom{n}{j} \leq n^j / j! grows polynomially in n while |\lambda|^{n-j} \to 0 exponentially, each term tends to 0 as n \to \infty. So J_k(\lambda)^n \to 0, and hence T^n \to 0.
If |\lambda| \geq 1, the eigenvector v corresponding to \lambda satisfies T^n v = \lambda^n v, so \|T^n v\| = |\lambda|^n \|v\| \not\to 0. Thus T^n \not\to 0. \square
9.9 Matrix Exponential
The matrix exponential extends the exponential function to matrices, enabling solutions to systems of differential equations.
Definition 9.8 (Matrix exponential) For A \in M_n(\mathbb{F}), the matrix exponential is e^A = \sum_{k=0}^\infty \frac{A^k}{k!} = I + A + \frac{A^2}{2!} + \frac{A^3}{3!} + \cdots.
Theorem 9.15 The series defining e^A converges absolutely in any submultiplicative matrix norm.
Proof. In any submultiplicative norm (\|AB\| \le \|A\| \|B\|), we have \|A^k\| \le \|A\|^k. Thus \sum_{k=0}^\infty \left\|\frac{A^k}{k!}\right\| \le \sum_{k=0}^\infty \frac{\|A\|^k}{k!} = e^{\|A\|} < \infty. \quad \square
The matrix exponential satisfies e^0 = I, is always invertible with (e^A)^{-1} = e^{-A}, and satisfies e^{A+B} = e^A e^B whenever AB = BA. For diagonalizable A = PDP^{-1}, the series gives e^A = Pe^DP^{-1} where e^D = \operatorname{diag}(e^{\lambda_1}, \ldots, e^{\lambda_n}).
Example. For A = \begin{pmatrix} 0 & 1 \\ -1 & 0 \end{pmatrix} (the infinitesimal generator of rotation), the eigenvalues are \pm i and e^{tA} = \begin{pmatrix} \cos t & \sin t \\ -\sin t & \cos t \end{pmatrix}, a continuous family of rotations parametrized by t.
Chapter 10 introduces inner product spaces and examines operators preserving geometric structure. The spectral theorem shows that self-adjoint operators on inner product spaces always diagonalize with orthonormal eigenbases, providing geometric meaning to the abstract algebraic decomposition developed here. Normal operators admit similar spectral decompositions, and the interplay between algebraic and geometric structure governs the theory of operators on Hilbert spaces.
The conceptual framework—decomposition into invariant subspaces, eigenvalue characterization via characteristic polynomials, reduction to simplest form—extends far beyond finite dimensions. Compact operators on Banach spaces, differential operators on function spaces, and representations of groups all admit spectral decompositions generalizing the finite-dimensional theory. The machinery developed here provides the foundation for functional analysis, differential equations, and mathematical physics.