5 The Total Derivative
In Chapter 1.5 we defined differentiability for scalar functions f : U \to \mathbb{R}: f is differentiable at p if there exists a linear functional Df_p : \mathbb{R}^n \to \mathbb{R} such that f(p + v) = f(p) + Df_p(v) + o(\|v\|). Chapter 2 extended this idea to smooth maps between manifolds: the derivative Df_p : T_pM \to T_{f(p)}N is defined by pushing curves forward, and in charts it becomes a linear map between Euclidean spaces.
This chapter works out that Euclidean story in full. When the domain is an open set U \subset \mathbb{R}^n and the codomain is \mathbb{R}^m, the tangent spaces are canonically \mathbb{R}^n and \mathbb{R}^m, and the derivative reduces to a concrete linear map Df_a : \mathbb{R}^n \to \mathbb{R}^m approximating f near a uniformly in all directions. We identify its matrix — the Jacobian — prove the chain rule, and introduce partial derivatives as the entries of that matrix. Higher-order derivatives, the Hessian, and Taylor’s theorem are developed in the next chapter.
Throughout, U \subset \mathbb{R}^n and V \subset \mathbb{R}^m denote open sets.
5.1 Differentiability
On an open set U \subset \mathbb{R}^n every tangent vector at a is just a vector in \mathbb{R}^n: the line \gamma(t) = a + tv has velocity \gamma'(0) = v, and every v \in \mathbb{R}^n arises this way. The derivative Df_a is therefore a linear map \mathbb{R}^n \to \mathbb{R}^m, and the approximation condition is:
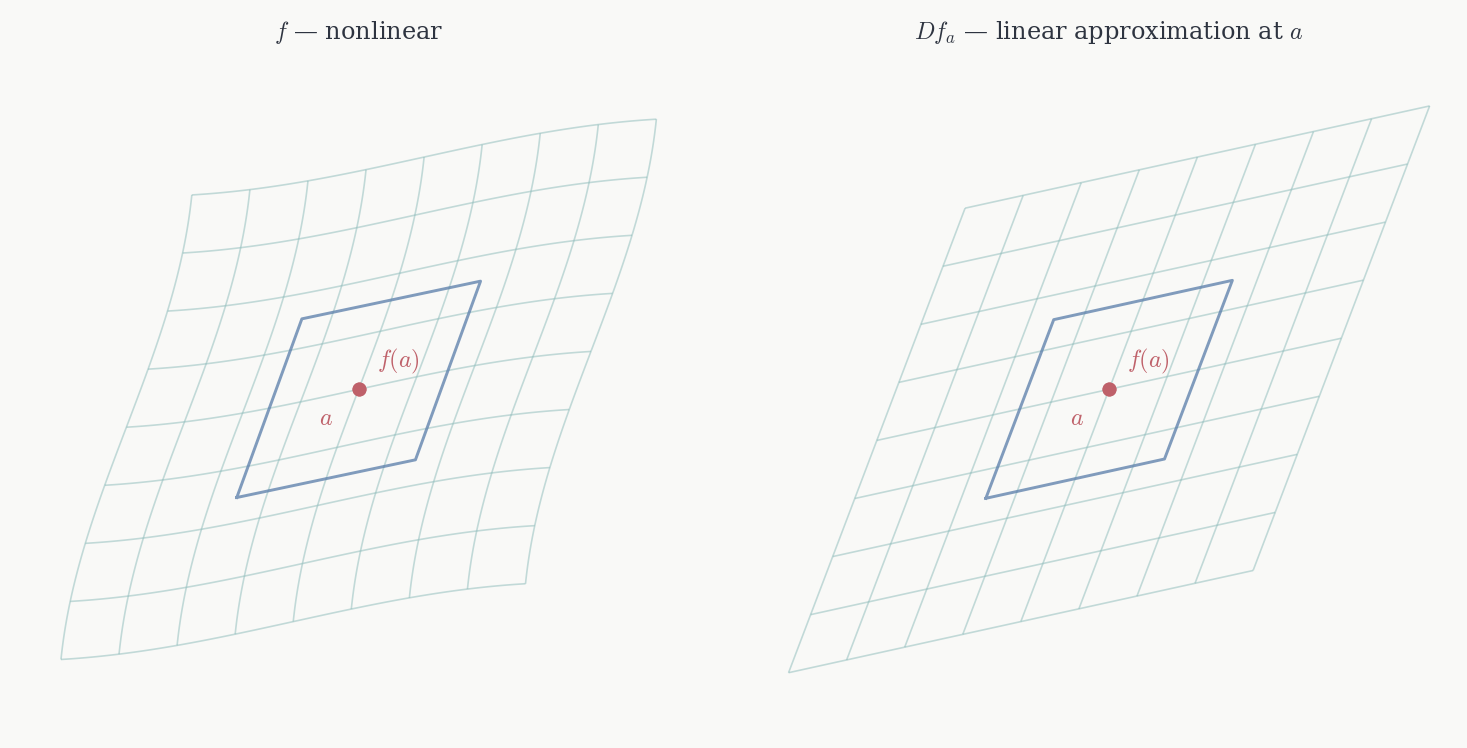
Definition 5.1 (Total derivative) f : U \to \mathbb{R}^m is differentiable at a if there exists a linear map Df_a : \mathbb{R}^n \to \mathbb{R}^m such that \lim_{h \to 0} \frac{\|f(a+h) - f(a) - Df_a(h)\|}{\|h\|} = 0. We call Df_a the total derivative of f at a. When f is differentiable at every a \in U we say f is differentiable on U.
Equivalently: f(a+h) = f(a) + Df_a(h) + o(\|h\|) as h \to 0. The remainder must be o(\|h\|) — vanishing faster than \|h\| — as h approaches 0 through all directions simultaneously, not just along lines. For n = m = 1 this recovers f(a+h) = f(a) + f'(a)h + o(h), the single-variable derivative.
The uniformity in all directions is the essential point, and it can fail even when every directional derivative exists.
Example. Define f : \mathbb{R}^2 \to \mathbb{R} by f(x,y) = \begin{cases} \dfrac{x^2 y}{x^4 + y^2} & (x,y) \neq 0, \\[6pt] 0 & (x,y) = 0. \end{cases} Along every line through the origin, f(tx, ty) = t^3 x^2 y/(t^4 x^4 + t^2 y^2) \to 0 as t \to 0, so every directional derivative at the origin is zero. The only candidate total derivative is Df_0 = 0. But along the parabola y = x^2: f(x,x^2) = x^4/(2x^4) = 1/2 for all x \neq 0, so \|f(h) - f(0) - 0\|/\|h\| does not go to zero. f is not differentiable at 0.
The failure here is that the directional derivatives, while all zero, do not control f in directions that curve — and the o(\|h\|) condition requires control over all paths, not just straight lines.
Two basic consequences of differentiability:
Theorem 5.1 (Uniqueness of the total derivative) If f is differentiable at a, the map Df_a is unique.
Proof. If L_1 and L_2 both satisfy the definition, then for any fixed v \neq 0, substituting h = tv and dividing by t > 0: \frac{\|(L_1 - L_2)(v)\|}{\|v\|} = \frac{\|(L_1-L_2)(tv)\|}{\|tv\|} \to 0. So (L_1 - L_2)(v) = 0 for every v. \square
Theorem 5.2 (Differentiability implies continuity) If f is differentiable at a, it is continuous at a.
Proof. \|f(a+h) - f(a)\| \leq \|Df_a(h)\| + o(\|h\|) \leq (\|Df_a\| + o(1))\|h\| \to 0 as h \to 0. \square
5.2 The Jacobian
The total derivative Df_a : \mathbb{R}^n \to \mathbb{R}^m is a linear map between finite-dimensional spaces. Every such map has a matrix once bases are chosen: the j-th column is the image of the j-th basis vector. With the standard bases on \mathbb{R}^n and \mathbb{R}^m, this matrix is the Jacobian.
Definition 5.2 (Jacobian matrix) The Jacobian of f at a is the m \times n matrix J_f(a) representing Df_a in the standard bases: Df_a(h) = J_f(a)\,h \qquad \text{for all } h \in \mathbb{R}^n.
The j-th column of J_f(a) is Df_a(e_j), the image of the j-th standard basis vector. This image has an explicit formula: setting h = te_j in the definition of Df_a and letting t \to 0, Df_a(e_j) = \lim_{t \to 0} \frac{f(a + te_j) - f(a)}{t}. This limit — differentiating f in the j-th coordinate direction while holding all others fixed — is the j-th partial derivative of f at a, written \partial_j f(a) or \partial f/\partial x_j(a). So the (i,j) entry of the Jacobian is: [J_f(a)]_{ij} = \partial_j f_i(a) = \lim_{t \to 0} \frac{f_i(a + te_j) - f_i(a)}{t}, and the full Jacobian is J_f(a) = \begin{pmatrix} \partial_1 f_1(a) & \cdots & \partial_n f_1(a) \\ \vdots & \ddots & \vdots \\ \partial_1 f_m(a) & \cdots & \partial_n f_m(a) \end{pmatrix}. Row i contains the partial derivatives of the i-th component of f; column j records how all components of f change when only x_j moves.
The relationship between Df_a and J_f(a) is exactly the relationship between a linear map and its matrix. The map Df_a is intrinsic — it does not depend on any coordinate choice. The Jacobian J_f(a) is its representation in the standard bases, and it changes if the bases change, exactly as the matrix [T]_\mathcal{B} of a linear operator changes when \mathcal{B} changes. The chain rule, proved below, describes precisely how the Jacobian transforms under a change of coordinates.
Important caveat. The existence of all partial derivatives at a does not imply differentiability. Partial derivatives probe f along coordinate lines only; differentiability requires a uniform linear approximation in all directions. The function f(x,y) = \begin{cases} xy/(x^2+y^2) & (x,y) \neq 0 \\ 0 & (x,y)=0 \end{cases} — the same function from Chapter 1 where we showed the limit at the origin does not exist — has \partial_1 f(0) = \partial_2 f(0) = 0 (since f(t,0) = f(0,t) = 0), yet is not even continuous at the origin. Partial derivatives exist; differentiability fails completely.
The correct sufficient condition is continuous partial derivatives, proved in the next chapter once the partial derivative theory is developed.

5.3 Regularity
Definition 5.3 (C^k maps) f : U \to \mathbb{R}^m is C^1 if it is differentiable on U and the map a \mapsto Df_a is continuous. It is C^k if Df is C^{k-1}, and smooth (or C^\infty) if it is C^k for every k \geq 1.
Continuity of a \mapsto Df_a is equivalent — as we prove in the next chapter — to continuity of all partial derivatives \partial_j f_i. So in practice: f is C^1 iff all its first-order partial derivatives exist and are continuous, and f is C^k iff all partial derivatives of order up to k exist and are continuous.
Every C^1 map is differentiable — this is the C^1 implies differentiable theorem of the next chapter. The converse fails: a function can be differentiable without being C^1. Every smooth map we encounter in practice is C^\infty.
5.4 The Chain Rule
Theorem 5.3 (Chain rule) Let f : U \to V be differentiable at a and g : V \to \mathbb{R}^k differentiable at f(a). Then g \circ f is differentiable at a and D(g \circ f)_a = Dg_{f(a)} \circ Df_a. In terms of Jacobians: J_{g \circ f}(a) = J_g(f(a))\, J_f(a).
Proof. Write b = f(a) and record the two approximations: f(a+h) = b + Df_a(h) + \|h\|\,\varepsilon_1(h), \qquad \varepsilon_1(h) \to 0, g(b+k) = g(b) + Dg_b(k) + \|k\|\,\varepsilon_2(k), \qquad \varepsilon_2(k) \to 0. Set k = f(a+h) - b = Df_a(h) + \|h\|\varepsilon_1(h) and substitute into the second: g(f(a+h)) - g(f(a)) - Dg_b(Df_a(h)) = Dg_b(\|h\|\varepsilon_1(h)) + \|k\|\,\varepsilon_2(k). Divide by \|h\|. The first term vanishes since \|Dg_b\|\|\varepsilon_1(h)\| \to 0. For the second, \|k\|/\|h\| \leq \|Df_a\| + \|\varepsilon_1(h)\| is bounded, and \varepsilon_2(k) \to 0 as h \to 0 (since k \to 0 when h \to 0). \square
The coordinate statement J_{g \circ f}(a) = J_g(f(a))\, J_f(a) is matrix multiplication — and it is not commutative, reflecting that the order of composition matters. The intrinsic statement D(g \circ f)_a = Dg_{f(a)} \circ Df_a says the same thing without bases: the derivative of a composition is the composition of the derivatives.
This is the chain rule used in Chapters 1.5 and 2 to conclude that velocity vectors lie in \ker DF_p (see Theorem 3.2): differentiating F \circ \gamma = 0 gives DF_p(\gamma'(0)) = 0. That step was stated without proof there; the theorem above is its justification.
Directional derivatives from the chain rule. For any v \in \mathbb{R}^n, the curve \gamma(t) = a + tv has \gamma'(0) = v. Applying the chain rule to f \circ \gamma at t = 0: (f \circ \gamma)'(0) = Df_a(\gamma'(0)) = Df_a(v) = J_f(a)\,v. The directional derivative of f at a in direction v is J_f(a)\,v — the Jacobian acting on v. In particular, setting v = e_j recovers \partial_j f(a) = J_f(a)\,e_j, the j-th column of the Jacobian. All directional derivatives are encoded in the single linear map Df_a; the Jacobian matrix extracts them all at once.
Example: the chain rule in coordinates. Let f : \mathbb{R}^2 \to \mathbb{R}^2 and g : \mathbb{R}^2 \to \mathbb{R}. Write f = (f_1, f_2). The chain rule J_{g \circ f}(a) = J_g(f(a))\,J_f(a) becomes the single equation \partial_\ell(g \circ f)(a) = \sum_{j=1}^{2} \frac{\partial g}{\partial y_j}(f(a))\,\frac{\partial f_j}{\partial x_\ell}(a). Each intermediate variable y_j = f_j(x) contributes through the product of the two rates of change. This is the familiar chain rule formula from single-variable calculus, now tracking all paths through the intermediate variables simultaneously.
Example: polar coordinates. Let \phi(r, \theta) = (r\cos\theta, r\sin\theta) and \tilde{f} = f \circ \phi for a scalar f : \mathbb{R}^2 \to \mathbb{R}. The chain rule gives: \frac{\partial \tilde{f}}{\partial r} = \frac{\partial f}{\partial x}\cos\theta + \frac{\partial f}{\partial y}\sin\theta, \qquad \frac{\partial \tilde{f}}{\partial \theta} = -\frac{\partial f}{\partial x}\,r\sin\theta + \frac{\partial f}{\partial y}\,r\cos\theta. The function f is unchanged; only its coordinate representation changes. The chain rule tracks exactly how the partial derivatives transform.
5.5 The Mean Value Inequality
The single-variable mean value theorem f(b) - f(a) = f'(c)(b-a) does not hold as an equality for vector-valued maps — there need not be a single point c where the derivative equals the average rate of change. The correct generalisation is an inequality.
Theorem 5.4 (Mean value inequality) Let f : U \to \mathbb{R}^m be differentiable on the open convex set U. For a, b \in U: \|f(b) - f(a)\| \leq \|b - a\| \sup_{t \in [0,1]} \|Df_{a+t(b-a)}\|.
Proof. The segment \gamma(t) = a + t(b-a) lies in U by convexity, and (f \circ \gamma)'(t) = Df_{\gamma(t)}(b-a) by the chain rule. The single-variable estimate \|f(b) - f(a)\| = \|\int_0^1 (f\circ\gamma)'(t)\,dt\| \leq \int_0^1 \|Df_{\gamma(t)}\|\|b-a\|\,dt gives the result. \square
The mean value inequality is the workhorse for proving that differentiable functions with bounded derivatives cannot change too fast. It will be used in the proofs of the inverse and implicit function theorems.